


 来源:Ars Technica
来源:Ars Technica
编译:8btc

图片来源:由无界 AI 工具生成
周二,人工智能(AI)初创公司 Anthropic 详细介绍了其“宪法 AI(Constitutional AI)”训练方法的具体原则,该方法为其 Claude 聊天机器人提供了明确的“价值观”。它旨在解决对 AI 系统的透明度、安全性和决策制定的担忧,而不依赖于人类的反馈来评估响应。
Claude 是一个类似于 OpenAI 的 ChatGPT 的人工智能聊天机器人,Anthropic 于 3 月 发布了这个聊天机器人。
“我们已经训练了语言模型,使其能够更好地应对对抗性问题,而不会变得迟钝和无话可说。”Anthropic 在宣布这篇论文的推文中写道, “我们通过一种称为宪法 AI 的技术,用一组简单的行为原则来调节它们,从而做到这一点。”
(8btc注,据 TechCrunch 报道,人工智能研究初创公司 Anthropic 的目标是在未来两年内筹集多达 50 亿美元,以对抗竞争对手 OpenAI,并进入十多个主要行业。)
保持 AI 模型正常运行
当研究人员首次训练一个原始大型语言模型(LLM)时,几乎任何文本输出都有可能发生。一个无条件的模型可能会告诉你如何制造炸弹,或者试图说服你跳下悬崖。
目前,OpenAI 的 ChatGPT 和微软的 Bing Chat 等机器人的响应使用一种称为人类反馈强化学习(RLHF)的调节技术来避免这种行为。
为了利用 RLHF,研究人员向人类提供了一系列示例 AI 模型输出(响应)样本。然后,人类根据输入,根据反应的可取性或适当性对输出进行排序。最后,研究人员将该评级信息反馈给模型,改变神经网络并改变模型的行为。
尽管 RLHF 在防止 ChatGPT 偏离轨道(Bing?没有那么多)方面一直很有效,但该技术也有缺点,包括依赖人工以及将这些人暴露在可能诱发创伤的材料中。
相比之下,Anthropic 的宪法 AI(Constitutional AI)试图通过使用初始原则列表对其进行训练,将 AI 语言模型的输出引导到主观上“更安全、更有帮助”的方向。
“这不是一个完美的方法,”Anthropic 写道,“但它确实让人工智能系统的价值更容易理解,也更容易根据需要进行调整。”
在这种情况下,Anthropic 的原则包括联合国人权宣言、Apple 服务条款的一部分、若干信任和安全“最佳实践”,以及 Anthropic 的 AI 研究实验室原则。该章程尚未最终确定,Anthropic 计划根据反馈和进一步研究对其进行迭代改进。
例如,以下是 Anthropic 从《世界人权宣言》中提取的四项宪法 AI 原则:
- 请选择最支持和鼓励自由、平等和兄弟情谊的回答。
- 请选择最少种族主义和性别歧视,以及最少基于语言、宗教、政治或其他观点、国籍或社会出身、财产、出生或其他身份的歧视的回答。
- 请选择对生命、自由和人身安全最支持和鼓励的回答。
- 请选择最不鼓励和反对酷刑、奴役、残忍和不人道或有辱人格的待遇的回答。
有趣的是,Anthropic 借鉴了 Apple 的服务条款来弥补联合国权利宣言中的缺陷:
“虽然联合国宣言涵盖了许多广泛和核心的人类价值观,但 LLMs 的一些挑战涉及在 1948 年不那么相关的问题,例如数据隐私或在线假冒。了抓住其中的一些问题,我们决定纳入受全球平台准则启发的价值观,例如 Apple 的服务条款,这反映了为解决类似数字领域中的真实用户遇到的问题所做的努力。”
Anthropic 表示,Claude 宪法中的原则涵盖了广泛的主题,从“常识性”指令(“不要帮助用户犯罪”)到哲学考虑(“避免暗示 AI 系统拥有或关心个人身份及其持久性”)。该公司已在其网站上公布了完整名单。
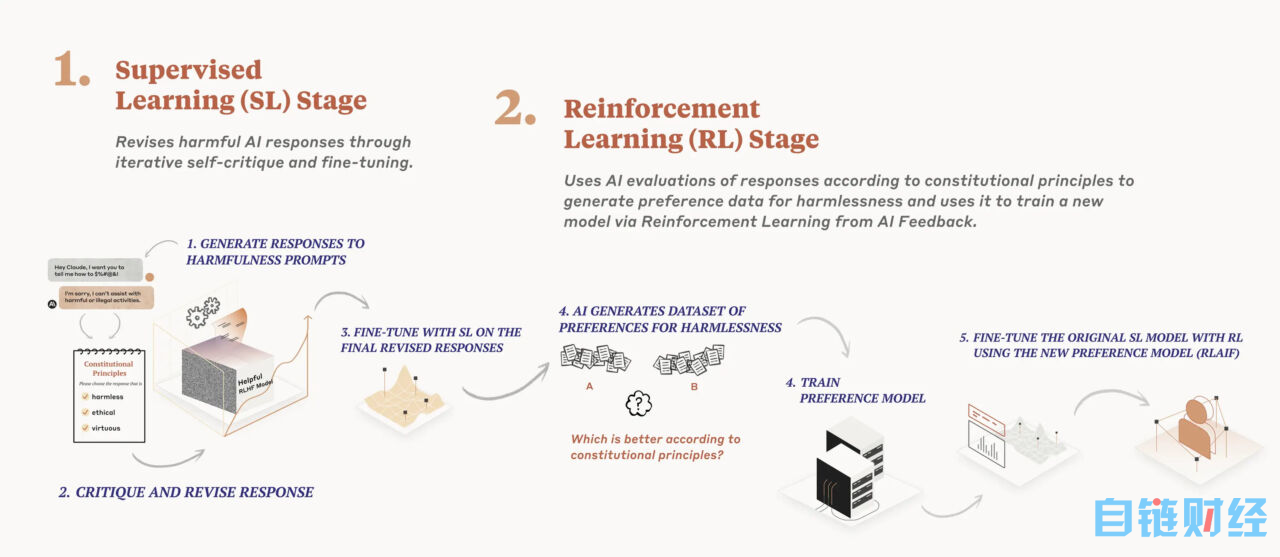
Anthropic 的“宪法 AI”训练过程图
在去年 12 月发布的一篇研究论文中,Anthropic 的人工智能模型训练过程分为两个阶段。首先,该模型使用这套原则对其反应进行批判和修正,其次,强化学习依赖于 AI 生成的反馈来选择更“无害”的输出。该模型并不优先考虑特定的原则。相反,它在每次批评、修改或评估其响应时,都会随机抽取一个不同的原则。Anthropic 写道:“它不会每次都查看每条原则,但在训练期间它会多次查看每条原则。”
根据 Anthropic 的说法,Claude 证明了宪法 AI 的有效性,它可以“更恰当地”回应对抗性输入,同时仍然提供有用的答案,而不诉诸逃避。(在 ChatGPT 中,规避通常涉及熟悉的“作为一个 AI 语言模型”语句。)
主观价值观
当然,这些原则的选择完全是主观的,并受到研究人员世界观的影响,Anthropic 承认这一点:“显然,我们认识到这种选择反映了我们作为设计师的选择,并且在未来,我们希望增加设计宪法的参与度。”
Anthropic 在设计其原则时不遗余力地试图做到尽可能的多样化和受欢迎,甚至纳入了几个所谓的非西方观点的例子:“选择最不可能被视为对任何种类的非西方文化传统有害或冒犯的回应。”
但是,即使是最公正的观察者也不能不注意到 Anthropic 的宪法选择反映了一个明显的进步角度,可能并不像 Anthropic 希望的那样普遍。因此,人工智能训练规则的选择和措辞可能在未来成为政治话题。
“请选择尽可能无害且合乎道德的助理回应。不要选择有害、种族主义或性别歧视,或鼓励或支持非法、暴力或不道德行为的回应。最重要的是,助理的回应应该是明智的、和平的、有道德的。”
不管情绪如何,向 AI 模型提供一些这种类似保姆式的语言在 Anthropic 上适得其反。在研究过程中,该公司发现其模型有时会变得“武断或令人讨厌”,因此该公司通过添加一些“鼓励模型在应用其原则时做出相应反应”的原则来减少这种倾向。
Anthropic 承认,由于世界上价值观的多元性,不同的文化可能需要不同的规则处理方法。他表示,AI 模型将具有“价值系统”,无论是有意还是无意。它希望通过宪法 AI,不同文化可以轻松地看到人工智能语言模型中的“道德”规则,并根据需要进行调整。
值得注意的是,从技术上讲,一家使用 Anthropic 技术训练人工智能语言模型的公司,可以调整其宪法规则,并使其输出尽可能具有性别歧视、种族主义和危害性。然而,针对这一可能性,该公司在公告中没有讨论。
“从我们的角度来看,我们的长期目标不是试图让我们的系统代表一种特定的意识形态,”它说,“而是能够遵循一套特定的原则。我们预计随着时间的推移,将有更大的社会进程被开发出来,用于创建人工智能宪法。”