


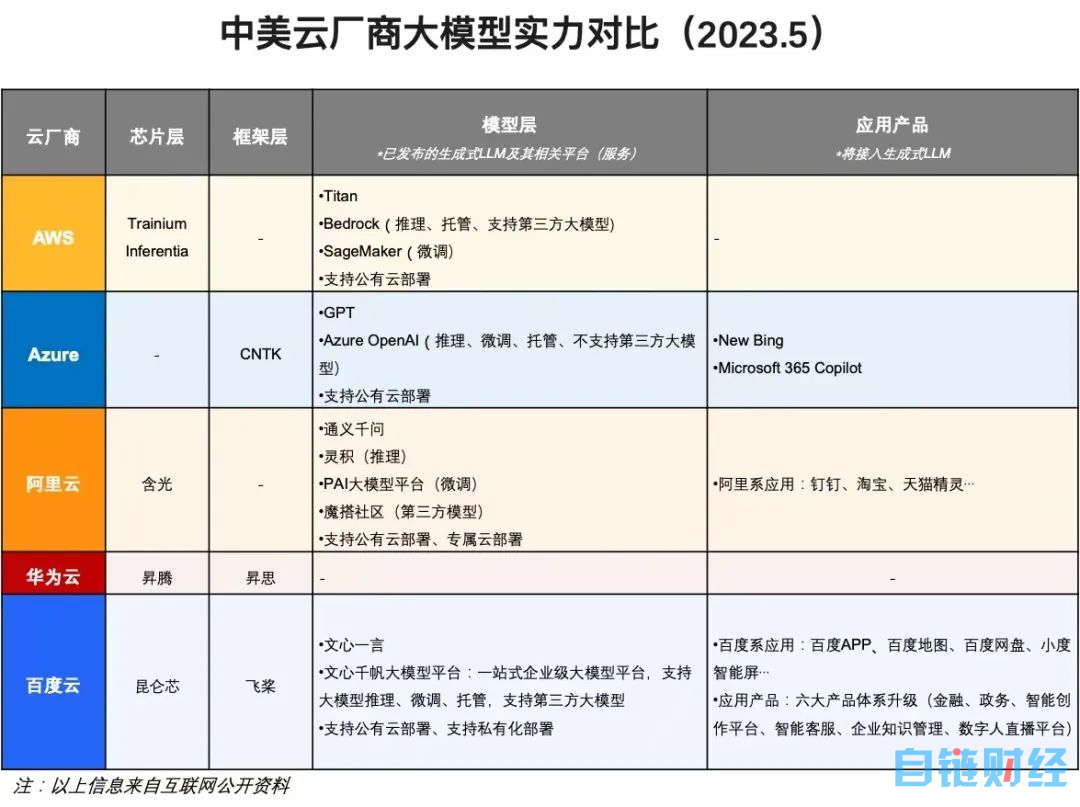
 原创:赵晋杰
原创:赵晋杰
来源:字母榜

图片来源:由无界 AI工具生成
国内科技大厂,在大模型竞争上再一次取得共识:既要做淘金者,也要卖铲子。
进入 4 月份,阿里云一边发布通用大模型“通义千问”,一边致力于帮助其他企业打造专属大模型。一位接近阿里云的人士表示,阿里云“甚至可以只卖铲子”。
尚未公开内测自有大模型产品的腾讯和字节跳动,也抢先盯上了卖铲子的生意。
腾讯云发布了面向大模型训练的新一代 HCC(High-Performance Computing Cluster)高性能计算集群,通过搭载英伟达最新 H800 GPU,将整体性能提升了 3 倍。
字节更是明确表态,火山引擎不做大模型,而是要为大模型客户提供算力平台,帮助其做好大模型开发。
在阿里、腾讯、字节相继决定卖铲子之前,百度其实是这一策略的更早提出者。但百度不同的是,前述大厂们都是在卖算力,百度更多是聚焦在服务。
在百度看来,支撑大模型训练和运转的算力固然重要,但不是评判大模型优劣的唯一标准。好的大模型需要由算力、框架、模型、应用构筑的四层架构相互配合提供支撑,需要将模型开发、训练、调优、运营等复杂过程封装起来,为客户提供低门槛、高效率的企业服务。
有百度内部人士告诉字母榜,在率先发布国内首个大语言模型文心一言后,3 月底的一场闭门沟通会上,百度就推出了“既淘金又卖铲子”的百度智能云大模型平台,并在近期正式将其命名为“文心千帆大模型服务平台”。
据字母榜了解,正在内测的“文心千帆大模型平台”,是全球首个一站式的企业级大模型生产平台,不但提供包括文心一言在内的大模型及第三方大模型服务,还提供大模型开发和应用的整套工具链,允许企业基于任何开源或闭源的大模型,开发自己的专属大模型。
在卖铲子上达成新共识后,头部云厂商之间的大模型之战,开始深入 AIGC+Application 的软件应用开发。
这也是时下投资机构最为青睐的方向之一。线性资本创始合伙人兼 CEO 王淮就表示,这是自己特别看重并且愿意花力气去挖掘的领域。今年上半年,线性资本至少看了两三百个基于大模型开发的各类应用。
已经走向全面开放或内测阶段的大模型产品提供商,由此掀起新一轮的应用生态建设竞赛。
OpenAI 发布了 ChatGPT Plugins 插件功能,开始将大模型能力直连第三方应用;微软推出了 AI 版 Office“全家桶”——Microsoft 365 Copilot,并将其测试企业数量从最初的 20 家,在近期扩展到 600 多家。
截至 5 月上旬,百度文心一言的内测企业数量超过 300 家,并在 400 多个企业内部场景取得了测试成效。
然而,目前企业应用大模型仍面临诸多难点,如模型体积大,训练难度高;算力规模大,性能要求高;数据规模大,数据质量参差不齐。
随着越来越多应用与大模型相结合,其也将倒逼云厂商对自己的大模型服务体系进行升维,走向一条追求更好效果、更低成本的道路。
通过全栈自研体系的端到端整体优势,百度智能云在实现大模型训练成本降低的同时,做到大模型产品服务体验的不掉队,破除外界评判大模型优劣时唯算力论的极端观点。
百度集团副总裁侯震宇告诉字母榜,在接下来几个月,百度大模型服务通过迭代优化,还将实现大规模的成本下降,不仅算力不会成为阻碍,“价格应该也不会成为大家所使用或者是拥抱大模型的瓶颈。”
A
“同样 60000 字的文本回复量,一个人工客服,一天的成本在 100 元 – 200 元,换用大模型智能助理,成本只有 1 块钱。”将大模型产品引入客服体系进行内测后,一家旅游行业业务负责人直观感受到了大模型带来的降本增效成果。相关产品未来会在完成安全评估后上线。
一些昔日垂类明星企业,股价甚至被大模型直接冲垮。美国学生习惯用以搜索课堂作业答案的在线教育公司 Chegg,成为全球首家公开承认“收入受 ChatGPT 影响”的公司,公司股价年内跌幅接近 60%。
网络流量数据网站 SimilarWeb 给出的一份报告显示,今年 3 月份 GPT-4、微软 New Bing 等产品陆续上线后,Chegg 网站转化访问量同比暴跌 89%。
对于企业来说,接入大模型产品已经从一道选择题,变成了必答题。
考虑到各行各业都有自己的 Know-How,在远望资本程浩看来,这正是头部云厂商纷纷发力卖铲子生意,帮助企业打造行业专属大模型的动因之一。
但并不是每一家企业都需要从 0 到 1,自主研发一个百亿、千亿的大模型产品。去年春节开始决定将办公文档引入大模型产品后,金山办公就明确好了甲方心态——自己不做大模型,而是借助外部已有大模型方案,定制自己的专属大模型。
在当前大模型尚缺乏评判好坏的统一客观标准之下,如何在“百模大战”中挑选出适合自己的大模型产品,正在成为企业面临的一道新难题。
金山办公助理总裁田然表示,公司的策略是要跟中国最好的大模型服务提供方站在一起,这势必要求大模型技术提供商做到“人无我有,人有我优”。
效果好不好,无疑会成为企业评判大模型产品好坏的首要标准。这一方面要看大模型产品是否已经有了大规模应用,如百度文心一言,已经在内部的百度搜索、百度新闻、百度地图,小度智能屏、如流等等方面实现大规模落地,并籍此成为国内唯一将大模型在实际应用中大规模落地的公司。
另一方面还要看大模型是否足够灵活便捷。基于文心千帆大模型平台,百度智能云提供公有云和私有云双重部署方案,并分别配套有大模型推理、微调、托管,软件授权、软硬一体和租赁等多元化服务。
金山办公由此看中了文心千帆在安全合规、模型深度、迭代速度、推理性能等多个方面的行业比较优势。目前,双方在意图理解、PPT 大纲生成、范文书写、生成待办列表、文生图等多模态生成场景上的联合探索开发,已经取得了进展。
金山办公 CEO 章庆元在接受采访中提到,成本是打消公司自研大模型念头的重要考虑因素。基于此,运行成本成为企业评判大模型产品好坏的另一决定因素。
运行大模型有多少烧钱?从 OpenAI 身上就能略窥一二。近期,OpenAI 被爆出去年亏损额翻倍,达到 5.4 亿美元左右,主要都被用以支撑 ChatGPT 的运转以及从谷歌挖人。
OpenAI CEO Sam Altman 更是表示,OpenAI 可能需要在未来几年尝试筹集多达 1000 亿美元的资金,用来开发足够先进的通用 AI,同时维持公司的正常运转。
在追赶 OpenAI 的道路上,后进者是否也要做好巨额亏损的准备?百度集团副总裁侯震宇向字母榜解释道,“这或许说明微软的云服务卖得太奢侈了。”

百度集团副总裁侯震宇
一个明显的佐证是,2023 年一季度,微软云计算毛利率达到 72%,而国内云计算厂商大多还处于亏损阶段。
为了降低用云成本,微软、谷歌等美国头部云厂商开始加速自研服务器芯片和云端 AI 芯片。
“如果你能制造出针对 AI 进行优化的硅,那前方等待你的将是巨大的胜利。”研究公司 Forrester 分析师格伦・奥唐纳形容道。
百度同样也在推进旗下芯片自研计划,其昆仑芯三代将对标更高性能的显卡,有望在 2024 年量产。
值得注意的是,除了芯片层的成本优化外,百度还是全球唯一一家在芯片层、框架层、模型层和应用层具备全栈协同优势的云厂商。
借助端到端的整体优化能力,在文心一言开启内测近两个月以来,百度已经对其进行了 4 次技术版本升级,并将大模型推理成本降至原来的十分之一。
在接下来几个月,百度大模型服务通过端到端的迭代升级,还可以实现大规模的成本下降,“价格应该不会成为大家所使用或者是拥抱大模型的瓶颈。”侯震宇表示。
通过百度过去近两个月在大模型落地应用上的实践经验,侯震宇总结出了企业选择大模型的三个标准评判:大模型本身的能力、大模型企业服务的能力、全栈技术积累程度。
B
持续不断的 AI 创新和研发投入,无疑将成为支撑大模型效果和成本持续优化的源动力。
但一则令 AI 创业者略感恐慌的消息却在近期被证实。一度引领全球 AI 发展方向的谷歌,为了不再为他人作嫁衣,正式决定“以后将不得不推迟与外界分享自己的工作成果”。谷歌人工智能主管杰夫・迪恩对此表示,背靠微软的创业公司 OpenAI,正是在大量阅读谷歌提交的 AI 论文基础上,才做到了与谷歌保持同步。
令 OpenAI 火遍全球的 ChatGPT,其中的 T——Transformer,就是谷歌 2017 年在一篇 AI 论文中率先提出的概念。
在侯震宇看来,谷歌关闭基础性 AI 研究的分享举动,更多影响到的是那些在 AI 领域没有自我积淀和独特优势的公司。
当所有公司都无法再依靠谷歌来为自己辨明 AI 方向后,此举反过来却可能为国内科技大厂创造出一个新的竞争优势。
近期,李彦宏在谈及当下的大模型混战中,就提到“算力不能保证我们能够在通用人工智能技术上领先,算力是可以买来的,创新的能力是买不来的,是需要自建的。”
作为一款对标 ChatGPT 的产品,百度文心一言,背后包括有监督精调、人类反馈的强化学习、提示、知识增强、检索增强和对话增强等六大关键技术。
“前三项是这类大语言模型都会采用的技术……后三项则是百度已有技术优势的再创新,也是文心一言未来越来越强大的基础。”百度 CTO 王海峰解释道,如通过知识增强,文心一言可以在调用更少参数的基础上,达到效率更高、效果更好的目标。
这一创新优势同样适合于企业借助文心千帆大模型平台,通过数据微调,打造自己的专属大模型产品。
在 5 月 9 日的一场闭门交流会上,百度首次对外演示了如何微调行业专属大模型的全过程。在文心一言基础上,百度内部测试了一款专属大模型“文心问数”,希望来展示数据的可视化能力。这也是国内第一个公开演示如何微调大模型。
在被要求其生成华北地区乃至全国 2019 年 3 月销售额时,“文心问数”顺利生成了饼状图等可视化图标。
但在将难度升级,要求其生成“华北地区 2019 年 3-5 月的销售额,用折线图来表示”时,“文心问数”直接表示自己处理不了。
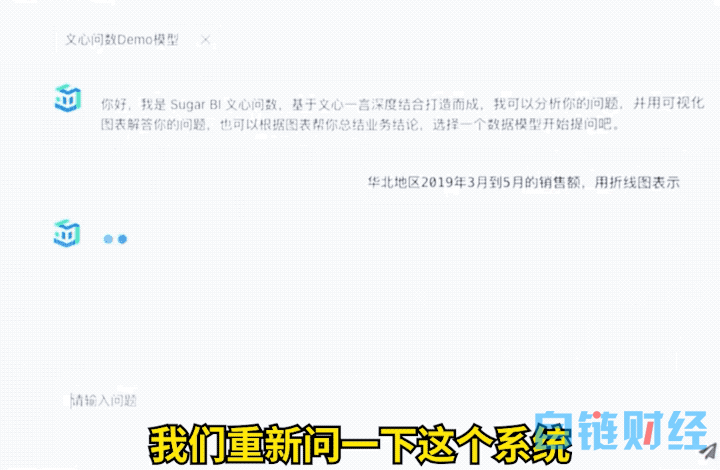
借助文心千帆大模型平台,这家公司只需新建一个包括约 100 条标注数据的微调数据集,发起模型微调,不到半个小时,就能完成对专属大模型的能力升级。
升级后的“文心问数”,不仅能够顺利完成特定指令和要求,并且对于同类需求还有一定的泛化能力。
C
大模型给传统应用带来的大幅体验升级,让越来越多人开始认同一种观点,即所有应用都值得用大模型重做一遍。
如同 Windows 带动了 PC 普及,Android 催生了移动互联网的生态,AIGC 时代“将诞生比移动互联网大十倍的平台机会,将把既有的软件、使用界面和应用重写一次。”李开复预测道。
眼下,百度等国产大模型厂商,正处于一场争夺 AIGC 时代“Android”的激烈竞争中。谁能抢先拿下更多的企业客户,谁就有望凭借“滚雪球效应”脱颖而出。
这是一场面向 AIGC 时代应用生态开发标准的抢位战,比的是谁能跑得更快,谁能拿到更多的反馈数据,谁能建立更多的应用落地优势。
尽管各家大模型产品在技术上大同小异,但大语言模型也是有“方言”的,相关产业专家表示,不同的大语言模型因为训练的数据分布不同,构造高质量数据不同,决定着用户提问的方式、调教和使用的方式也不尽相同。
就像开发者在不同手机操作系统上开发一款游戏,尽管最终游戏效果、赛制差不多,但分属不同操作系统的游戏好友,是没办法进行排位等操作的。一旦企业用了某个大语言模型,再切换到别的大模型,迁移成本会很高。
“这也造成了谁能够跑得更快一些,获取更多的应用,拿到更多的反馈,谁就能持续地保持一定程度的领先。”上述专家表示。
大模型不仅将成为新的应用生态的 Game Changer,当越来越多客户基于大模型重塑业务后,大模型还有望成为云服务行业的 Game Changer,彻底改变云计算的游戏规则。
在李彦宏看来,过去,云计算主要卖算力,看速度、看存储。今天,客户购买云服务,则要看框架好不好、模型好不好。MaaS(模型即服务),将成为评判云服务的行业新标准。
更重要的是,在移动互联网时代已经划分好市场地位的云厂商,面对 AIGC 时代的新机遇,有望重塑行业格局。
美国第四大云计算厂商甲骨文,在过去一个月内,因为头部云厂商算力紧缺,甲骨文模型服务更便宜,已经吸引不少人工智能初创企业转而成为甲骨文的新客户。
随着越来越多企业将更多业务融入大模型,当 AI 能力逐步放大变成企业上云的主要需求后,如百度这类押注 AI 的云厂商,无疑将走上一条快速道。