



写在前面:由于以太坊1.0当前所采用的数据结构,以太坊的状态爆炸问题使其全节点的运行要求变得越来高,为了解决这一困境,研究者们提出了两种解决方案,一是状态租赁,另一个就是所谓的“无状态客户端”,而V神最近提出的eth1-> eth2合并方案中就要求使用到“无状态客户端”,那这一概念到底是指什么呢,它的研发现状又如何?发布在以太坊基金会官网的新文章《无状态以太坊的研发进展》一文将给出答案,原文作者是Griffin Ichiba Hotchkiss。

以下是译文:
在上一篇关于以太坊1.x的文章中,我们对Eth 1.x研究计划的起源、面临的风险以及一些可能的解决方案做了快速的介绍。我们以无状态以太坊的概念结束,并把关于无状态客户端更详细的内容留给了这篇文章。
无状态(Stateless)是Eth 1.x研究的新方向,因此我们将做一次相当深入的研究,真正去了解关于这一方向在未来道路上的挑战和可能性。对于那些想要深入研究的读者,我会尽我所能地把相关资源的链接放出来。
无状态以太坊的状态
要想知道我们要去往哪里,我们首先必须理解“状态”的概念。当我们说“状态”的时候,它的意思是指“事务的状态”。
以太坊的完整“状态”描述了所有账户和余额的当前状态,以及在EVM中部署和运行的所有智能合约的集体记忆。链中每个最终确定的区块,都有且只有一个状态,这是由网络中的所有参与者共同商定的。该状态将随添加到链中的每个新区块而发生更改和更新。
在Eth 1.x研究的背景下,我们不仅要知道状态是什么,还要知道它在协议(如黄皮书中定义的)和大多数客户端实现(如geth、parity、trinity、besu等)中是如何表示的。
什么是trie?
以太坊所使用的数据结构我们称之为MTP(Merkle Patricia Trie),有趣的事实是:“Trie最初取自‘retrieval’一词,但大多数人在在念它时会将它发音为‘try’,以区别于‘tree’。” 好吧,我离题了。关于MTP数据结构,我们需要了解的是:
在trie的一端,有描述状态(值节点)的所有特定数据片段。这可以是特定帐户的余额,也可以是存储在智能合约中的变量(例如ERC-20 token的总供应量)。中间则是分支节点,其通过哈希运算(hashing)将所有值链接在一起。分支节点是包含其子节点哈希的数组(array),每个分支节点随后被哈希处理并放入其父节点的数组中。这个连续哈希最终会到达trie另一端的一个状态根节点。
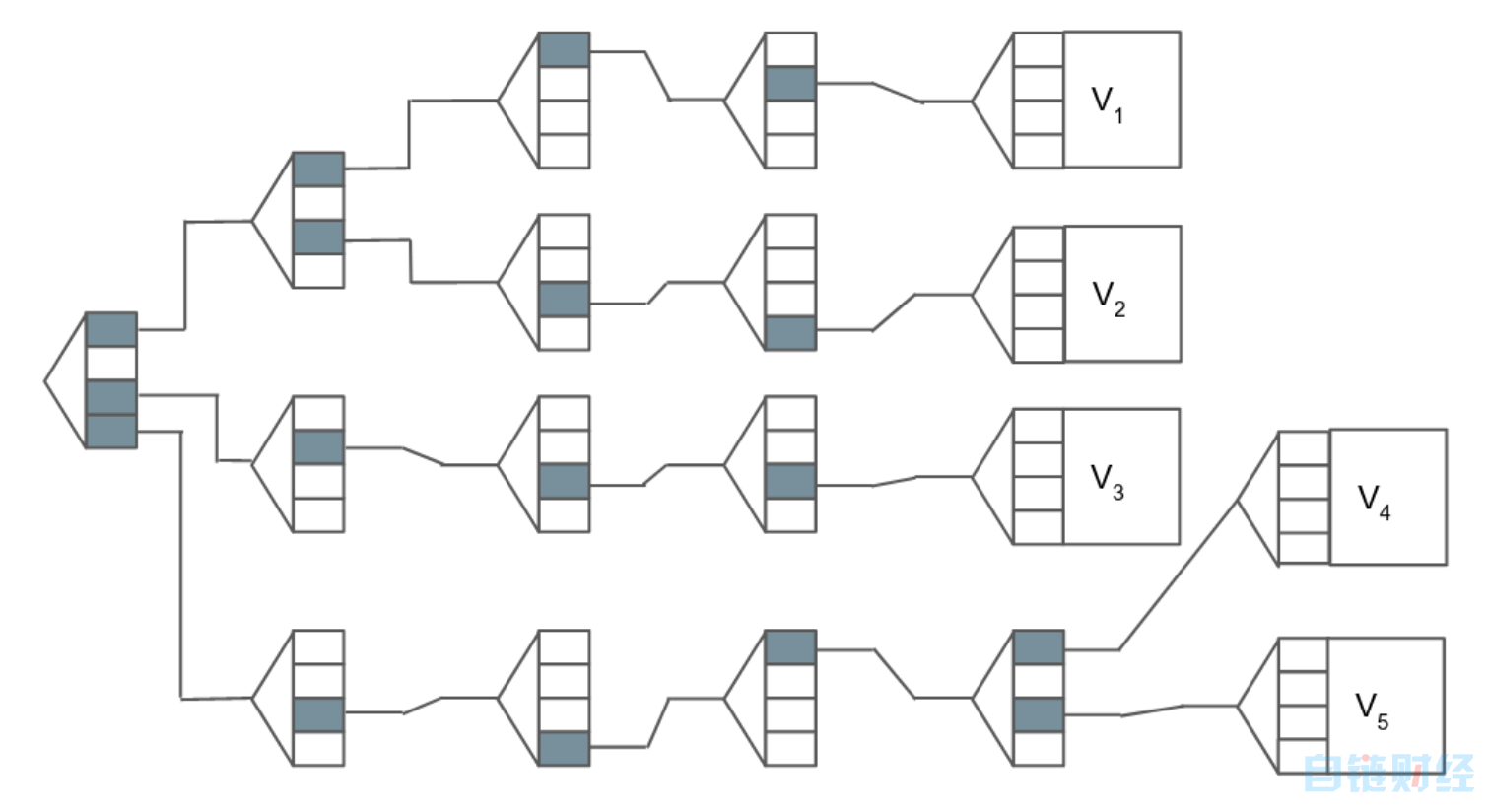
在上面的简化图中,我们可以看到每个值,以及描述如何获取这些值的路径(path)。例如,为了得到V-2,我们遍历路径1,3,3,4。类似地,V-3可通过遍历路径3,2,3,3来实现。请注意,本例子中的路径长度始终为4个字符,并且通常只有一条路径可用于获取值。
这种结构具有确定性和可加密验证的重要特性:生成状态根的唯一方法,是从状态的每个单独部分计算它,通过比较根哈希和导致它的哈希(Merkle证明),可以很容易地证明两个相同的状态。相反,无法使用相同的根哈希创建两个不同的状态,任何试图使用不同值修改状态的尝试,都将导致不同的状态根哈希。
以太坊通过引入一些提高效率的新节点类型(扩展节点和叶节点)来优化trie结构。它们将路径的一部分编码为节点,这样trie就更加紧凑。
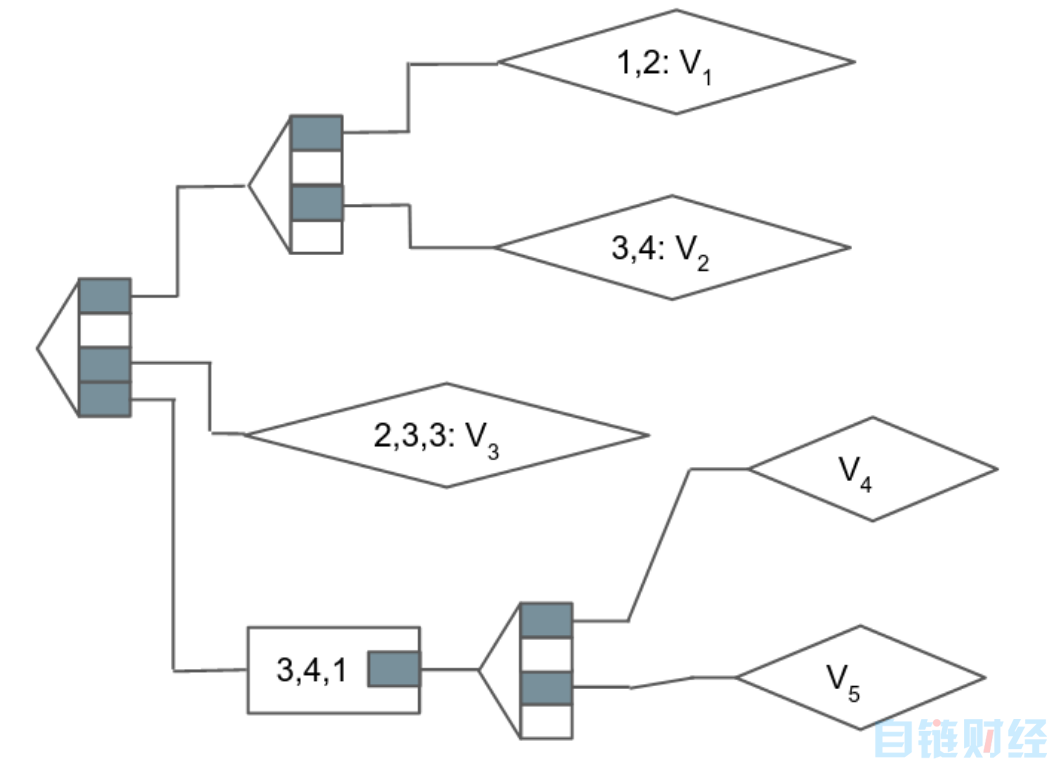
在这种改进版MTP结构中,每个节点将导致在多个后续节点共享的路径的压缩部分或值之间进行选择。它是相同的数据和相同的组织,但是这个trie结构只需要9个节点而不是18个节点。这看起来会更有效率,但实际来看,它并不是最理想的。我们将在下一节探讨原因。
要到达状态的特定部分(例如账户当前的ETH余额),需要从状态根开始,沿着trie从一个节点爬至另一个节点,直到达到所需的值。在每个节点上,路径中的字符,被用于决定下一个要移动到的节点是哪个(就像是一个占卜棒,但它是用于导航哈希数据结构的)。
而在以太坊所使用的“真实”版本数据结构中,路径(path)是长度为64个字符(256位)的地址哈希,值(value)是RLP编码数据。分支节点是包含17个元素的数组(其中有16个是每个可能的十六进制字符,剩余一个则为value),而叶节点和扩展节点包含2个元素(一个是部分路径,另一个是下一个子节点的值或哈希)。关于这方面的内容,以太坊wiki页面可能是最佳的选择,或者,如果你喜欢钻到杂草丛中,那么这篇文章使用Python进行了一个很棒的DIY-trie练习(不幸的是,它被否决了)。
把它放到数据库里
此时我们应该提醒自己,trie结构只是一个抽象的概念。这是一种将以太坊状态的整体打包成一个统一结构的方法。然而,这种结构需要在客户端的代码中实现,并存储在磁盘上(或者分散在全球的数千个磁盘)。这意味着要采用多维trie并将其填充到一个普通的数据库中,而该数据库只理解[key,value]对。
在大多数以太坊客户端(turbo-geth 除外)中,MPT是通过为每个节点创建不同的 [key, value] 对来实现的,其中value是节点本身,而key是该节点的哈希。
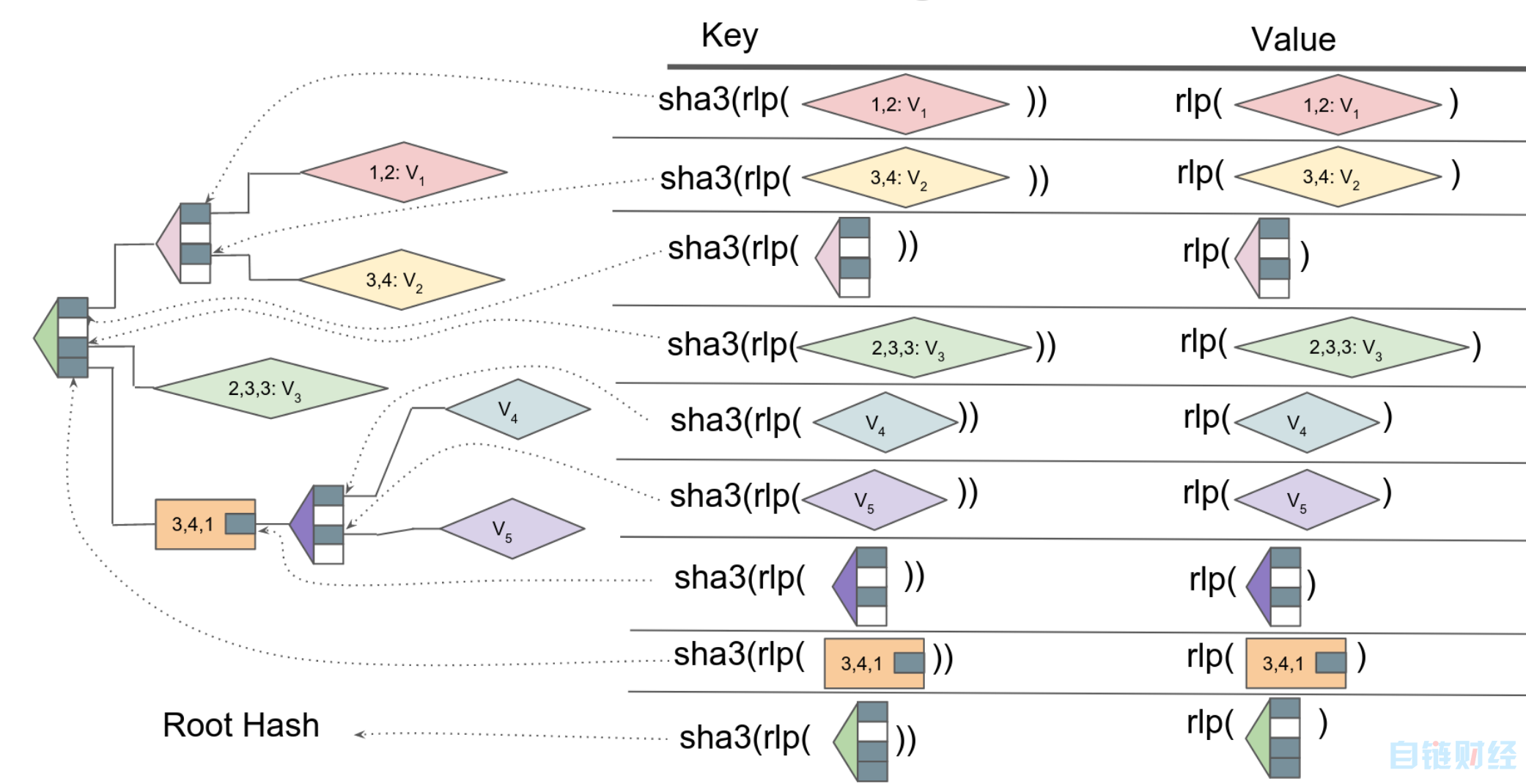
因此,遍历trie的过程,或多或少与前面描述的理论过程相同。要查找帐户余额,我们将从根哈希开始,并在数据库中查找其值以获取第一个分支节点。使用哈希地址的第一个字符,我们找到第一个节点的哈希。我们在数据库中查找哈希,然后得到第二个节点。使用哈希地址的下一个字符,我们找到第三个节点的哈希。如果幸运的话,我们可能会发现一个扩展节点或叶节点,而不需要遍历所有64个nibble,但最终,我们会找到所需的帐户,并能够从数据库中检索其余额。
计算每个新区块的哈希,在很大程度上有着相同的过程,但它是反过来的:从所有边缘节点(账户)开始,通过连续哈希来构建trie,直到最后构建一个新的根哈希,并与链中最后商定的区块进行比较。
这就是关于状态trie的表观效率:在磁盘上重新构建整个trie是非常密集的,以太坊使用的改进版MPT结构以实现效率为代价提高了协议效率。
这些额外的节点类型(叶节点和扩展节点)理论上节省了存储trie所需的内存,但它们使修改常规数据库中状态的算法更加复杂化。当然,一台功能强大的计算机,可以极快的速度执行这个过程。然而,纯粹的处理能力也会存在瓶颈。
同步,同步,是魔鬼的步伐
到目前为止,我们讨论的内容是运行在以太坊客户端(如geth)的单个计算机中发生的事情。但以太坊是一个网络,所有这一切的关键,是在全球数千台计算机以及不同客户端之间实现一个统一的状态共识。
不断洗牌的#Defi、cryptokitty拍卖或cheeze巫师大战的token,以及普通的ETH传输交易,都会结合在一起,为以太坊客户端创建快速变化的状态,而它们都需要保持同步(越变越难),随着以太坊变得更受欢迎,状态trie结构也会越来越深。
“Turbo-geth是解决根源问题的一种实现:它将trie数据库扁平化,并使用节点的路径(而不是其哈希)作为
[key, value]对。这有效地使树的深度与查找无关,并启用了各种漂亮的功能,这些功能可以在运行全节点时提高性能并减少磁盘负载。”
以太坊的状态是很大的,它会随每一个区块的变化而变化。那它的状态到底是有多大呢?每次变化又是多大?我们可以将以太坊的当前状态大致定位在状态trie的大约4亿个节点上,其中,大约每15秒需要添加或修改大约3000个(有时也多达6000个)节点。与以太坊区块链保持同步,实际上就是不断地构建新版本的状态trie。
“这种状态trie数据可操作的多步骤过程,正是以太坊客户端的磁盘I/O和内存占用如此庞大的原因,即便是“快速同步”模式也可能需要长达6个多小时的时间才能完成。而要运行一个以太坊全节点,你就要使用到快速SSD(而不是廉价的HDD),因为状态更改的处理,对磁盘读/写的要求是非常高的!”
这里很重要的一点在于,建立一个新节点,然后去同步,这与使用现有节点进行同步,两者之间存在着非常大的区别。而当我们实现无状态以太坊之后,(希望)它们之间的区别将会是模糊的。
同步节点的简单方法是使用“full sync”(完全同步)方法:从创始区块开始,检索每个区块中每笔交易的列表,并构建状态trie。对于每个后续区块,状态trie被修改,随着区块链完整历史的重播而添加和修改节点。而从一开始下载并执行每个区块的状态更改,需要同步者花费整整一周的时间。
而另一种方法,则被恰当地命名为“fast-sync”(快速同步),这种方式的速度更快,但也要更复杂:新客户端可以从最近受信任的‘检查点’(checkpoint)区块请求状态条目,而不是从头开始请求交易。这种方式下载的信息总量要少得多,但仍然有很多信息需要处理(同步目前不受带宽限制,而是受磁盘性能的限制)。
快速同步节点,本质上是与链的顶端竞争。它需要在‘检查点’(checkpoint)中获取所有状态,然后该状态变为陈旧状态并停止由全节点提供(如果发生这种情况,它可以‘转动’到新的检查点)。
一旦快速同步节点克服了障碍,并使其状态完全赶上检查点(checkpoint),它就可以切换到完全同步,即从每个区块中包含的交易生成并更新自己的状态副本。
区块验证(witness)内容又是什么?
现在,我们可以开始剖析无状态以太坊的概念。其中一个主要目标就是减少新节点同步过程的痛苦。考虑到只有0.1%的状态是从一个区块切换到另一个区块,似乎应该有一种方法,它可以减少在完全同步切换之前需要下载的所有额外“东西”。
但这是以太坊加密安全数据结构带来的挑战之一:在trie数据结构中,仅更改一个值就会导致完全不同的根哈希。这是一个功能,而不是一个漏洞!它使得每个人都能确信自己和网络上的其他人在同一个页面上(处于同一状态)。
为了走捷径,我们需要一条关于状态的新信息:区块验证(block witness)内容。
假设此trie结构中只有一个值最近发生了更改(下图中的绿色块部分):
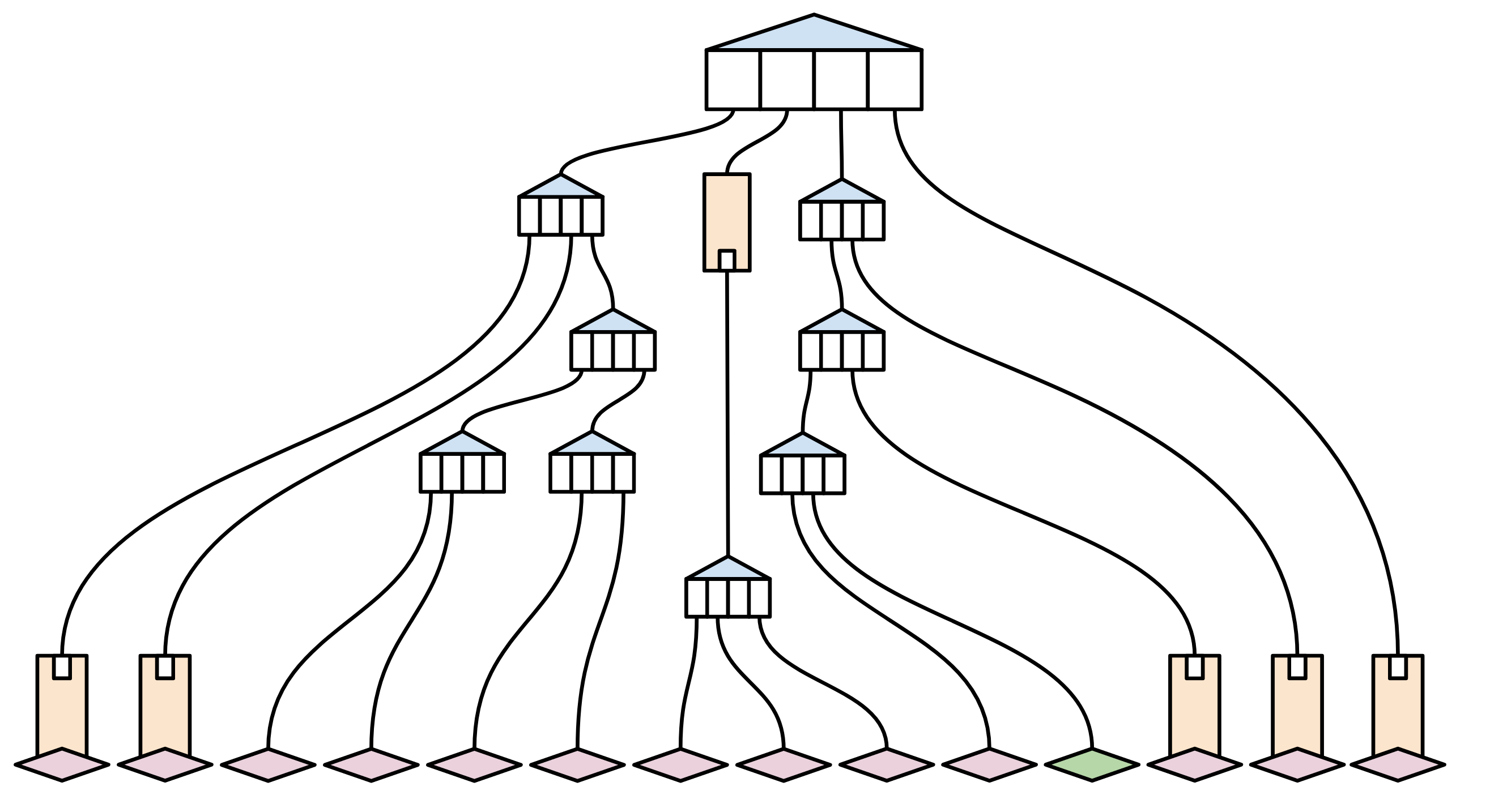
同步状态(包括这笔交易)的全节点将采用传统的方式:获取所有状态片段,并将它们哈希运算在一起,以创建新的根哈希。然后,它们可以很容易地验证自己的状态是否与其他所有人的状态相同(因为它们具有相同的哈希和相同的交易历史)。
那刚刚接收到消息的人呢?新节点进行验证所需的最小信息量是多少,以保证其观察结果与其它节点是一致的(至少在其观察的时间内如此)?
一个新的“菜鸟”节点将需要更老、更明智的全节点提供证据,证明观察到的交易符合它们迄今为止所看到的关于状态的一切。
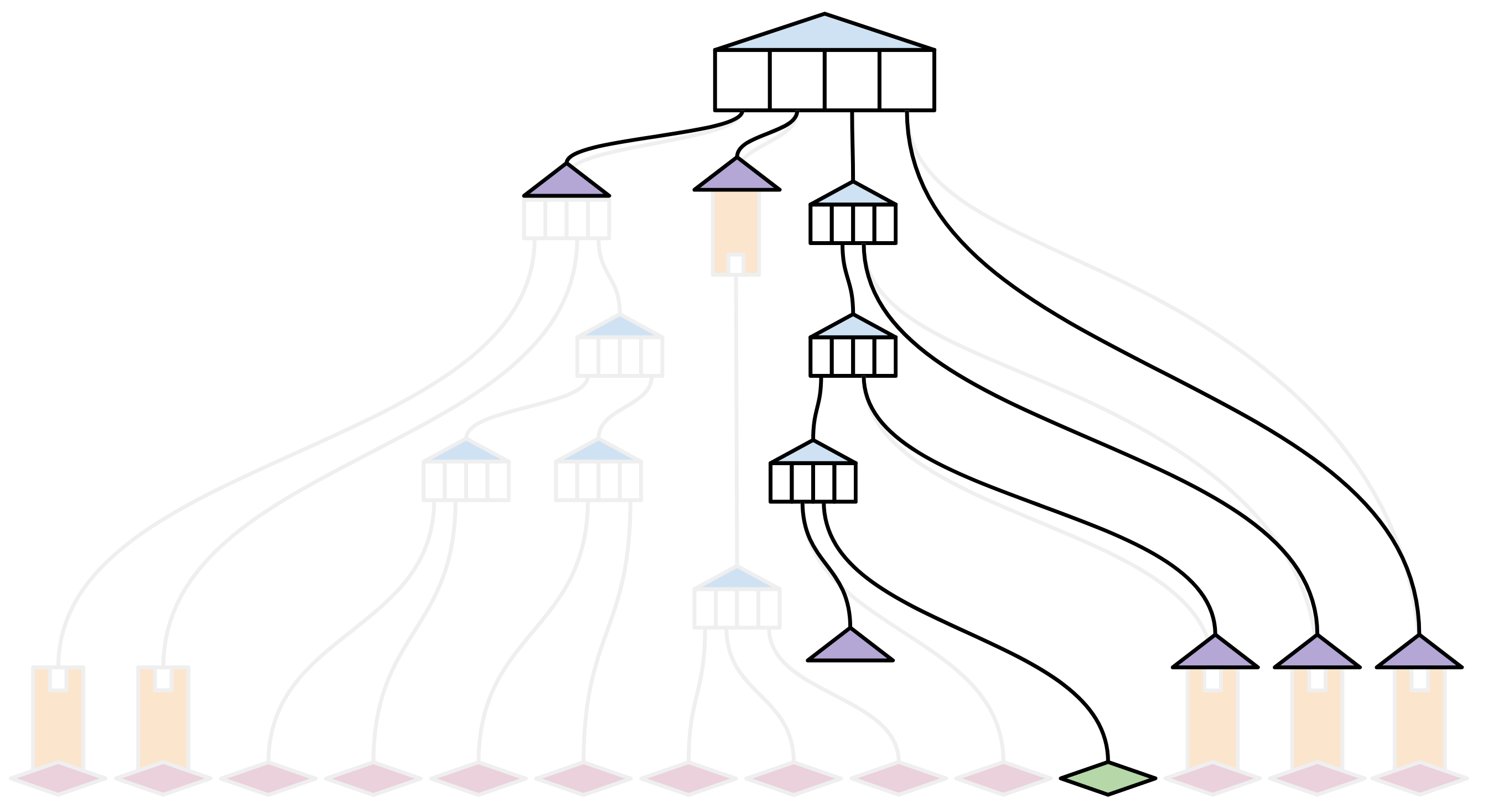
用非常抽象的术语来说,一个区块验证(witness)证明提供了状态trie中所有丢失的哈希,并结合了关于这些哈希在trie中属于何处的一些“结构”信息。这允许“萌新”节点将新交易包含在其状态中,并在本地计算新的根哈希,而不需要它们下载状态trie的整个副本。
简而言之,这就是beam同步( beam sync)背后的想法。Beam同步方案不再等待收集检查点trie中的每个节点,而是开始监视并尝试在交易发生时执行交易,从全节点请求每个区块的witness(验证)内容,以获取它没有的信息。
随着越来越多的状态被新交易“触及”,客户端可渐渐更多地依赖自己的状态副本,这通过beam同步逐渐填充,直到最终切换到完全同步。
无状态客户端的谱系
随着区块验证(witness)内容的引入,“完全无状态”的概念开始得到更多的定义。同时,这也是我们开始遇到开放性问题和没有明显解决方案的问题的地方。
与beam同步方案相比,真正的无状态客户端永远不会保留状态副本,它只会与验证(witness)内容一起获取最新的交易,并拥有执行下一个区块所需的一切。
你可能会看到,如果整个网络都是无状态的,那么这实际上可能会不断持续下去——新区块的验证(witness)内容可以从上一个区块产生,然后一路上都会有验证(witness)内容!至少,直到最后商定的“事务状态”,以及从该状态产生的第一个验证(witness)内容。而这对于以太坊来说是一个巨大而又戏剧性的改变,它不太可能会赢得广泛的支持。
一种不太引人注目的方法,是迎合不同程度的“无状态”,在这个网络当中,会有一些节点保存状态的完整副本,并且可为其它所有人提供新的验证(witness)内容。
- 其中,完整状态节点会像以前一样工作,但需要另外计算一个验证(witness)内容并将其附加到新区块,或通过辅助网络子协议传播它;
- 部分状态节点可以只在很短的一段时间内保持一个完整的状态,或者可能只“观察”它们感兴趣的一段状态,然后从验证(witness)内容那里获取它们验证区块所需的其余数据,这对dapp开发人员运行其基础设施而言将有很大的帮助;
- 根据定义,零状态节点希望使其客户端尽可能轻地运行,它们可以完全依赖验证(witness)内容来验证新的区块;
要使这个方案起作用,可能需要类似于bittorrent采用的分块(chunking)和群集(swarming)行为,其中验证(witness)内容片段根据其需要进行传播,并与具有(互补)部分状态的其他节点建立最佳连接。或者,它可能涉及制定一个更适合验证(witness)内容生成的状态trie的替代实施方案。而这些,就是我们需要去研究和实验的东西!
要更深入地分析有状态节点与无状态节点之间的权衡,请参见Alexey Akhunov的《The shades of statefulness》一文。
这种半-无状态方法的一个重要特点是,这些更改不一定要通过硬分叉方式进行。而通过小的、可测试和渐进的改进方式,可以将以太坊的无状态组件构建成一个补充型子协议,或者作为一系列没有争议的EIP,而不是作为一个大的“信心飞跃式”的升级。
关于无状态客户端的路线图
而研究室里的大象(译者注:指显而易见的问题)就是验证(witness)内容的大小。普通区块包含一个区块头(header)和交易列表,它们的大小约为100 kB。这是足够小的,其使得区块的传播相对于网络延迟及15秒的区块时间来说是很快了。
然而,验证(witness)内容需要在状态trie的边缘和深层包含节点的哈希。这意味着它们要大得多:早期的数据显示大约有1 MB。因此,与网络延迟和区块时间相比,同步验证(witness)内容要慢得多,这可能是一个问题。
这种困境类似于下载电影和流媒体电影之间的区别:如果网络过慢导致流媒体体验糟糕,那么下载完整的电影是唯一可行的选择。如果网络速度快得多,那你就可以毫无问题地播放电影。而处在中间,你就需要更多的数据来作出决定。那些低于标准的互联网服务提供商,将在高需求阶段认识到低速网络的局限性问题。
在很大程度上,这就是Eth 1x研发小组正在尝试解决的具体问题。目前,我们对假想验证网络的了解,还不足以确定它是否能正常或最佳地工作,主要的问题就在于细节(以及数据)。
一种方法是通过改变trie本身的结构(如二进制trie)来考虑压缩和减少验证(witness)内容数量的方法,以使其在实现层次上更有效。另一个则是原型化网络原语(bittorrent风格的swarming),允许验证(witness)内容有效地在网络上的不同节点之间传递。而这两个方案,都将受益于一个形式化验证(witness)内容规范(目前这个规范还不存在)。
研发人员会将以上这些方向(以及更多的可能)编写成一个路线图,并在未来几周内正式发布。路线图中强调的要点,也将是未来深度解析文章的主题。
如果你能理解上面的内容,那你应该对“无状态以太坊”的意义有了一个很好的了解,并知道了一些新兴Eth1x研发项目的背景。
与往常一样,如果你对Eth1x的努力、主题有任何疑问, 或者你想要为此进行贡献,请访问ethresear.ch并作自我介绍,或在twitter上联系@gichiba以及@JHancock。
特别感谢Alexey Akhunov提供的技术反馈以及一些trie结构示意图。
新年快乐,穆尔冰川硬分叉快乐!