


 原创丨张天蓉
原创丨张天蓉
来源丨 知识分子
于 2022 年底问世的 ChatGPT,震撼了互联网。不由得使人联想起 2016 年初的 AlphaGo,挑战人类顶级围棋大师李世石的故事。我在 2017 年出版的一本概率科普书中【1】,对当年人工智能的状况稍有描述,那算是 AI 的第二次革命,深度机器学习和自然语言处理(NLP)刚起步。没想到短短几年过去,第三次 AI 浪潮滚滚而来,基本搞定了自然语言的理解和生成难题,以 ChatGPT 发布为里程碑,开辟了人机自然交流的新纪元。

图 1:OpenAI 发布 ChatGPT
人工智能(AI)的想法由来已久,英国数学家艾伦・图灵,不仅仅是计算机之父,也设计了著名的图灵试验,开启了人工智能的大门。如今,人工智能的应用已渗入到我们的日常生活中。它的成功崛起,来源于计算机的飞速发展、云计算的兴起、大数据时代的来临,等等。其中,与大数据有关的数学基础主要是概率论。因此,此文就聊聊 ChatGPT 与概率相关的一个方面,更具体来说,是与几百年前的一个人名有关:贝叶斯。
概率论和贝叶斯
针对概率论,有法国牛顿之称的拉普拉斯(1749 年 – 1827 年)曾说:
“这门源自赌博机运之科学,必将成为人类知识中最重要的一部分,生活中大多数问题,都将只是概率的问题。”
两百多年之后的当今文明社会,证实了拉普拉斯的预言。这个世界充满了不确定性,处处是概率,万物皆随机。无需抽象定义,概率论的基本直观概念早已渗透到人们的工作和生活当中,小到人人都可以买到的彩票,大到星辰宇宙,复杂到计算机和人工智能,都与概率密切相关。
那么,贝叶斯又是谁呢?
托马斯・贝叶斯(Thomas Bayes,1701 年 – 1761 年),是 18 世纪的一位英国数学家、统计学家,他曾经是个牧师。不过他“生前籍籍无名,死后众人崇拜”,在当代科技界“红”了起来,原因归结于以他命名的著名的贝叶斯定理。这个定理不仅在历史上促成了贝叶斯学派的发展,现在又被广泛应用于与人工智能密切相关的机器学习中【2】。
贝叶斯做了些什么?当年,他研究一个“白球黑球”的概率问题。概率问题可以正向计算,也能反推回去。例如,盒子里有 10 个球,黑白两种颜色。如果我们知道 10 个球中 5 白 5 黑,那么,如果我问你,从中随机取出一个球,这个球是黑球的概率是多大?问题不难回答,当然是 50%!如果 10 个球是 6 白 4 黑呢?取出一个球为黑的概率应该是 40%。再考虑复杂一点的情形:如果 10 个球中 2 白 8 黑,现在随机取 2 个球,得到 1 黑 1 白的概率是多少呢?10 个球取出 2 个的可能性总数为 10*9=90 种,1 黑 1 白的情况有 16 种,所求概率为 16/90,约等于 17.5%。因此,只需进行一些简单的排列组合运算,我们可以在 10 个球的各种分布情形下,计算取出 n 个球,其中 m 个是黑球的概率。这些都是正向计算概率的例子。
不过,当年的贝叶斯更感兴趣的是反过来的“逆概率问题”:假设我们预先并不知道盒子里黑球白球数目的比例,只知道总共是 10 个球,那么,比如说,我随机地拿出 3 个球,发现是 2 黑 1 白。逆概率问题则是要从这个试验样本(2 黑 1 白),猜测盒子里白球黑球的比例。
也可以从最简单的抛硬币试验来说明“逆概率”问题。假设我们不知道硬币是不是两面公平的,也就是说,不了解这枚硬币的物理偏向性,这时候,得到正面的概率 p 不一定等于 50%。那么,逆概率问题便是企图从某个(或数个)试验样本来猜测 p 的数值。
为了解决逆概率问题,贝叶斯在他的论文中提供了一种方法,即贝叶斯定理:
P (A|B) =(P (B|A) * P (A))/P (B) (1)
这儿,A、B 是两个随机事件,P (A)是 A 发生的概率;P (B)是 B 发生的概率。P (A|B)、P (B|A),称为条件概率:P (A|B)是在 B 发生的情况(条件)下 A 发生的概率;P (B|A)是在 A 发生的情况下 B 发生的概率。
应用贝叶斯定理的例子
可以从两个角度来解读贝叶斯定理:一是“表述了两个随机变量 A 和 B 的相互影响”;二是“如何修正先验概率而得到后验概率”,以下分别举例予以说明。
首先,初略地说,贝叶斯定理(1)涉及了两个随机变量 A 和 B,表示两个条件概率 P (A|B) 和 P (B|A)之间的关系。
例 1:某小城一月份治安不太好,30 天内发生入室抢劫案 6 起。警察局有一个警报器,有事发生时便会拉响,包括火灾、暴风雨等天灾,及偷盗、强奸一类的人祸。一月份时,警报器每天都响。并且,从过去的经验,如果有居民遭入室抢劫时,警报器响的概率是 0.85。现在人们又听到了警报声,那么,这次响声代表入室抢劫的概率是多少呢?
分析一下这个问题。A: 入室抢劫;B: 拉警报。然后,我们已知(一月份):
入室抢劫的概率 P (A) = 6/30 = 0.2;拉警报的概率 P (B) = 30/30 = 1;P (B|A) = 入室抢劫时拉警报的概率 = 0.85。
所以,根据公式(1),代入已知的 3 个概率,计算得到 P (A|B) =(0.85*0.2/1)= 0.17。
也就是说,这次“警报响的原因是有人入室抢劫”的概率是百分之十七。
下面举例说明如何用贝叶斯定理,从“先验概率”计算“后验概率”。首先将(1)改写为如下样子:
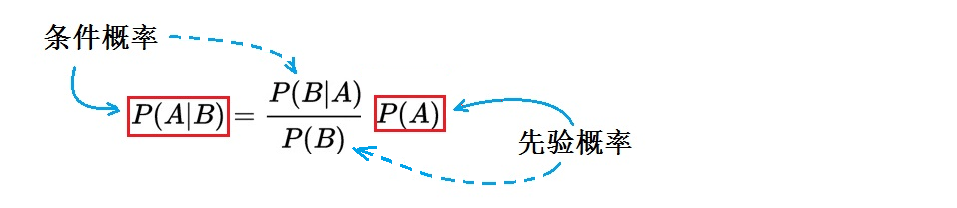
用一句话来概括(2),它说的是:利用 B 发生带来的新信息,可以修改当 B 未发生时 A 的“先验概率”P (A),从而得到 B 发生(或存在)时,A 的“后验概率”,即 P (A|B)。
首先用美国心理学家,2002 年诺贝尔经济奖得主丹尼尔・卡尼曼举的一个例子简单说明。
例 2:某城市有两种颜色(蓝绿)的出租车:蓝车和绿车的比率是 15:85。某日某辆出租车夜间肇事后逃逸,但当时正好有一位目击证人,这位目击者认定肇事的出租车是蓝色的。但是,他“目击的可信度”如何呢?公安人员经过在相同环境下对该目击者进行“蓝绿”测试而得到:80% 的情况下识别正确,20% 的情况不正确,问题是计算肇事之车是蓝色的几率。
假设 A = 车为蓝色、B = 目击蓝色。首先我们考虑蓝绿出租车的基本比例(15: 85)。也就是说,在没有目击证人的情况下,肇事之车是蓝色的几率为 15%,这是“A = 蓝车肇事”的先验概率 P (A)= 15%。
现在,有了一位目击者,便改变了事件 A 出现的概率。目击者看到车是“蓝”色的。不过,他的目击能力也要打折扣,只有 80% 的准确率,即也是一个随机事件(记为 B)。我们的问题是要求出在有该目击证人“看到蓝车”的条件下肇事车“真正是蓝色”的概率,即条件概率 P (A|B)。后者应该大于先验概率 15%,因为目击者看到“蓝车”。如何修正先验概率?需要计算 P (B|A)和 P (B)。
因为 P (B|A)是在“车为蓝色”的条件下“目击蓝色”的概率,即 P (B|A) =80%。概率 P (B)的计算麻烦一点。P (B)指的是目击证人看到一辆车为蓝色的概率,应该等于两种情况的概率相加:一种是车为蓝色,辨认也正确;另一种是车为绿,错看成蓝。
所以:P (B) = 15%×80% + 85%×20% = 29%
从贝叶斯公式:
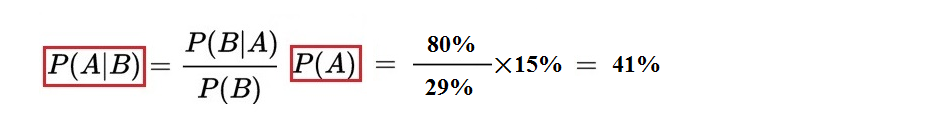
可以算出在有目击证人情况下肇事车辆是蓝色的几率 = 41%。由结果可见,被修正后的“肇事车辆为蓝色”的条件概率 41%,大于先验概率 15% 很多。
例 3:公式(2)中,“先验”和“后验”的定义是一种“约定俗成”,是相对而言的,前一次算出的后验概率,可作为后一次的先验概率,再与新的观察数据相结合,得到新的后验概率。因此,运用贝叶斯公式,可以对某种未知的不确定性逐次修正概率模型并得到最终的客观结果。
或者变个说法,有时也可以说,观察者根据贝叶斯公式和不断增加的数据,可能修正自己对某个事件的主观“信任度”。
以抛硬币为例,一般认为硬币是“公平”的。但是,造假的情况太多,结果需要要靠数据说话。
比如说,设命题 A 为:“这是一个公平硬币”,观测者对此命题的信任度用 P (A)表示。如果 P (A)=1,表示观测者坚信这个硬币是“正反”公平的;P (A)越小,观测者对硬币公平的信任度越低;如果 P (A)=0,说明观测者坚信这个硬币不公平,比如说,是一个造假的、两面都标志为“正面”的“正正”硬币。如果用 B 表示命题“这是一个正正硬币”的话,P (B) = 1- P (A)。
下面我们看看如何根据贝叶斯公式来更新观察者的“信任度”模型 P (A)。
首先,他假设一个“先验信任度”,比如 P (A)=0.9,0.9 接近 1,说明他比较偏向于相信这个硬币是公平的。然后,抛硬币 1 次,得到“正 Head”,他根据贝叶斯公式,将 P (A)更新为 P (A|H):

更新后的后验概率 P (A|H) = 0.82,然后,再抛一次,又得到正面(H),两次正面后新的更新值是 P (A|HH) = 0.69,三次正面后的更新值是 P (A|HHH) = 0.53。如此抛下去,如果 4 次接连都得到正面,新的更新值是 P (A|HHHH) = 0.36。这时候,这位观察者对这枚硬币是公平硬币的信任度降低了很多,从信任度降到 0.5 开始,他就已经怀疑这个硬币的公平性,接连 4 个正面后,他更偏向于认为该硬币很可能是一枚两面都是正面的假币!
从上面几个例子,我们初步了解了贝叶斯定理及其简单应用。
贝叶斯定理的意义
贝叶斯定理是贝叶斯对概率论和统计学作出的最大贡献,但在当年,贝叶斯的“逆向概率”研究和导出的贝叶斯定理看起来平淡无奇,未引人注意,贝叶斯也名不见经传。如今看来完全不应该是这样,贝叶斯公式的重要意义,是如例 3 所示的那种探知未知概率的方法。人们首先有一个先验猜测,然后结合观测数据,修正先验,得到更为合理的后验概率。这就是说,当你不能准确知悉某个事物本质时,你可以依靠经验去对未知世界的状态步步逼近,从而判断其本质属性。实际上,它的思想之深刻远出一般人所能认知,也许贝叶斯自己生前对此也认识不足。因为如此重要的成果,他生前却并未发表,是他死后的 1763 年,才由朋友发表的。后来,拉普拉斯证明了贝叶斯定理的更普遍的版本,并将之用于天体力学和医学统计中。如今,贝叶斯定理更是当今人工智能中常用的机器学习之基础框架【3】。
贝叶斯定理与当时的经典统计学相悖,甚至显得有些“不科学”。因此它多年来一直被雪藏,不受科学家待见。从上一节例 3 可见,贝叶斯定理的应用方法是建立在主观判断的基础上,先主观猜测一个值,然后根据经验事实不断地修正,最后得到客观世界的本质。实际上,这正是科学的方法,也是人类从儿童开始,认知世界(学习)的方法。所以可以说,近年来人工智能研究的兴旺发达,关键之一是来自于经典计算技术和概率统计的“联姻”。而其中的贝叶斯公式概括了人们学习过程的原则,如果配合上大数据的训练,便有可能更确切地模拟人脑,教会机器“学习”,便能加速 AI 的进展。从目前情况看,也正是如此。
机器如何学习?
教机器学习,学些什么呢?实际上就是要学会如何处理数据,这也是大人教孩子学会的东西:从感官得到的大量数据中挖掘出有用的信息来。如果用数学的语言来叙述,就是从数据中建模,抽象出模型的参数【4】。
机器学习的任务,包括了“回归”、“分类”、等主要功能。回归是统计中常用的方法,目的是求解模型的参数,以便“回归”事物的本来面目。分类也是机器学习中的重要内容。将事物“分门别类”,也是人类从婴儿开始,对世界认知的第一步。妈妈教给孩子:这是狗,那是猫。这种学习方法属于“分类”,是在妈妈的指导下进行的“监督”学习。学习也可以是“无监督”的,比如说,孩子们看到了“天上飞的鸟、飞机”等,也看到了“水中游的鱼、潜艇”等,很自然地自己就能将这些事物分成“飞物”和“游物”两大类。
贝叶斯公式也可以用来将数据进行分类,下举一例说明。
假设我们测试了 1000 个水果的数据,包括如下三种特征:形状(长?)、味道(甜?)、颜色(黄?),这些水果有三种:苹果、香蕉、或梨子,如图 2 所示。现在,使用一个贝叶斯分类器,它将如何判定一个新给的水果的类别?比如说,这个水果三种特征全具备:长、甜、黄。那么,贝叶斯分类器应该可以根据已知的训练数据给出这个新数据水果是每种水果的概率。
首先看看,从 1000 个水果的数据中,我们能得到些什么?
1. 这些水果中,50% 是香蕉,30% 是苹果,20% 是梨子。也就是说,P(香蕉)= 0.5,P(苹果)= 0.3,P(梨子)= 0.2。
2. 500 个香蕉中,400 个(80%)是长的,350 个(70%)是甜的,450 个(90%)是黄的。也就是说,P(长 | 香蕉)= 0.8,P(甜 | 香蕉)= 0.7,P(黄 | 香蕉)= 0.9。
3. 300 个苹果中,0 个(0%)是长的,150 个(50%)是甜的,300 个(100%)是黄的。也就是说,P(长 | 苹果)= 0,P(甜 | 苹果)= 0.5,P(黄 | 苹果)= 1。
4. 200 个梨子中,100 个(50%)是长的,150 个(75%)是甜的,50 个(25%)是黄的。也就是说,P(长 | 梨子)= 0.5,P(甜 | 梨子)= 0.75,P(黄 | 梨子)= 0.25。
以上的叙述中,P (A|B)表示“条件 B 成立时 A 发生的概率”,比如说,P(甜 | 梨子)表示梨子甜的概率,P(梨子 | 甜)表示甜水果中,梨子出现的概率。
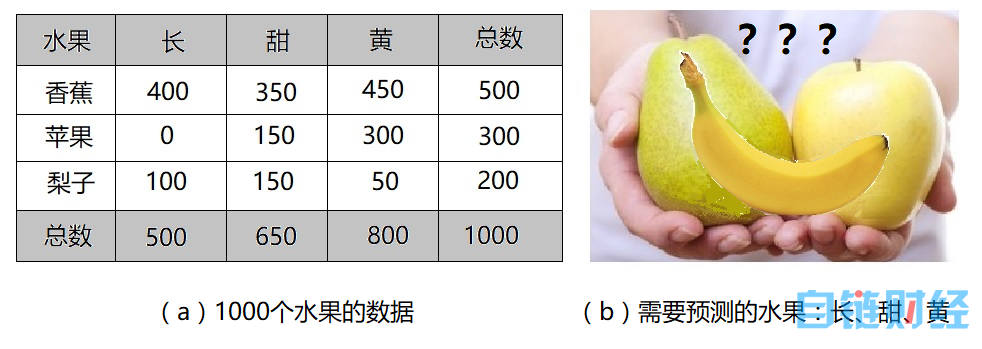
图 2:贝叶斯分类器
所谓“朴素贝叶斯分类器”,其中“朴素”一词的意思是说,数据中表达的信息是互相独立的,在该例子的具体情况下,就是说,水果的“长、甜、黄”这三项特征互相独立,因为它们分别描述水果的形状、味道和颜色,互不相关。“贝叶斯”一词便表明此类分类器利用贝叶斯公式来计算后验概率,即:P (A | 新数据)= P(新数据 | A) P (A)/P(新数据)。
这儿的“新数据”=“长甜黄”。下面分别计算在“长甜黄”条件下,这个水果是香蕉、苹果、梨子的概率。对香蕉而言:
P(香蕉 | 长甜黄)= P(长甜黄 | 香蕉)P(香蕉)/P(长甜黄)
等式右边第一项:P(长甜黄 | 香蕉)= P(长 | 香蕉)* P(甜 | 香蕉)* P(黄 | 香蕉)= 0.8*0.7*0.9 = 0.504。
以上计算中,将 P(长甜黄 | 香蕉)写成 3 个概率的乘积,便是因为特征互相独立的原因。
最后求得:P(香蕉 | 长甜黄)= 0.504*0.5/P(长甜黄)= 0.252/P(长甜黄)。
类似的方法用于计算苹果的概率:P(长甜黄 | 苹果)= P(长 | 苹果)*P(甜 | 苹果)* P(黄 | 苹果)= 0*0.5*1 = 0。P(苹果 | 长甜黄)= 0。
对梨子:P(长甜黄 | 梨子)= P(长 | 梨子)*P(甜 | 梨子)* P(黄 | 梨子)= 0.5*0.75*0.25 = 0.09375。P(梨子 | 长甜黄)= 0.01873/P(长甜黄)。
分母:P(长甜黄)= P(长甜黄 | 香蕉)P(香蕉)+ P(长甜黄 | 苹果)P(苹果)+ P(长甜黄 | 梨子)P(梨子)= 0.27073
最后可得:P(香蕉 | 长甜黄)= 93%
P(苹果 | 长甜黄)= 0
P(梨子 | 长甜黄)= 7%
因此,当你给我一个又长、又甜、又黄的水果,此例中曾经被 1000 个水果训练过的贝叶斯分类器得出的结论是:这个新水果不可能是苹果(概率 0%),有很小的概率(7%)是梨子,最大的可能性(93%)是香蕉。
深度学习的奥秘
再看看,孩子们是如何学会识别狗和猫的?是因为妈妈带他见识了各种狗和猫,多次的经验使他认识了狗和猫的多项特征,他便形成了自己的判断方法,将它们分成“猫”、“狗”两大类。科学家们也用类似的方法教机器学习。比如说,也许可以从耳朵来区别猫狗:“狗的耳朵长,猫的耳朵短”,还有“猫耳朵朝上,狗耳朵朝下”。根据这两个某些“猫狗”的特征,将得到的数据画在一个平面图中,如图 3 b 所示。这时候,有可能可以用图 3 b 中的一条直线 AB,很容易地将猫狗通过这两个特征分别开来。当然,这只是一个简单解释“特征”的例子,并不一定真能区分猫和狗。
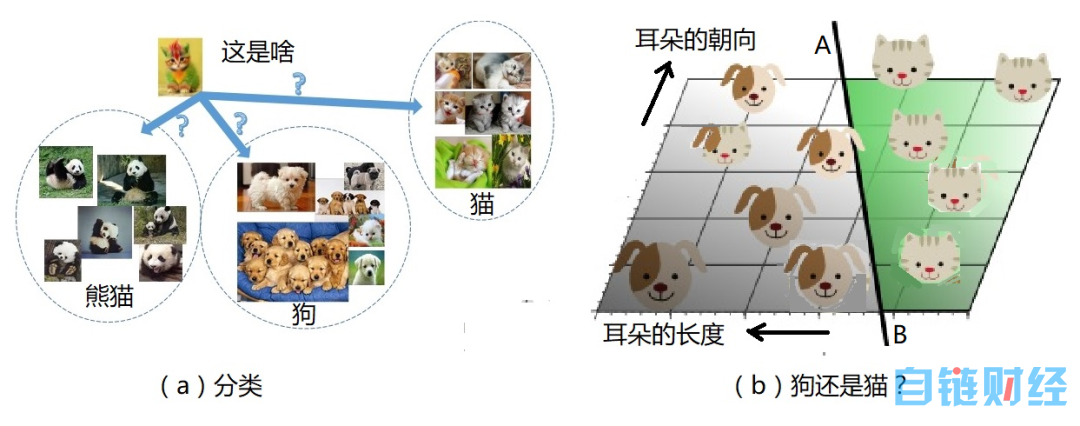
图 3:机器分类
总而言之,机器可以根据某个“特征”,将区域作一个线性划分。那么,这条线应该画在哪儿呢?这就是“训练”过程需要解决的问题。在机器模型中,有一些被称为“权重”的参数 w1、w2、w3,……,“训练”的过程就是调整这些参数,使得这条直线 AB 画在正确的位置,指向正确的方向。上述“猫狗”的例子中,输出可能是 0,或者 1,分别代表猫和狗。换言之,所谓“训练”,就是妈妈在教孩子认识猫和狗,对 AI 模型而言,就是输入大量“猫狗”的照片,这些照片都标记了正确的结果,AI 模型调节权重参数使输出符合已知答案。
经过训练后的 AI 模型,便可以用来识别没有标记答案的猫狗照片了。例如,对以上所述的例子:如果数据落在直线 AB 左边,输出“狗”,右边则输出“猫”。
图 3 b 表达的是很简单的情形,大多数情况下并不能用一条直线将两种类型截然分开,比如图 4 a、图 4 b、图 4 c 中所示的越来越复杂的情形,我们就不多谈了。
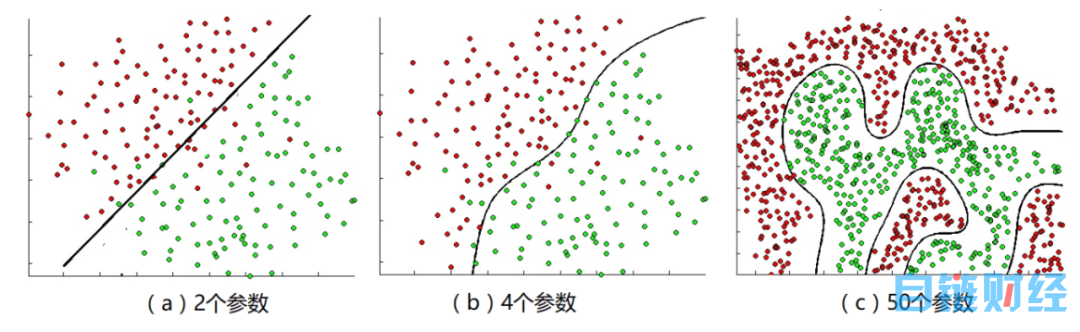
图 4:更多的特征需要更多的参数来识别
判别式和生成式
在机器学习中的监督学习模型,可以分为两种:判别式模型和生成式模型。从前面的叙述我们明白了机器如何“分类”。从这两种学习方式的名字,可以简单地理解为:判别式模型更多是考虑分类的问题,而生成式模型是要产生一个符合要求的样本。
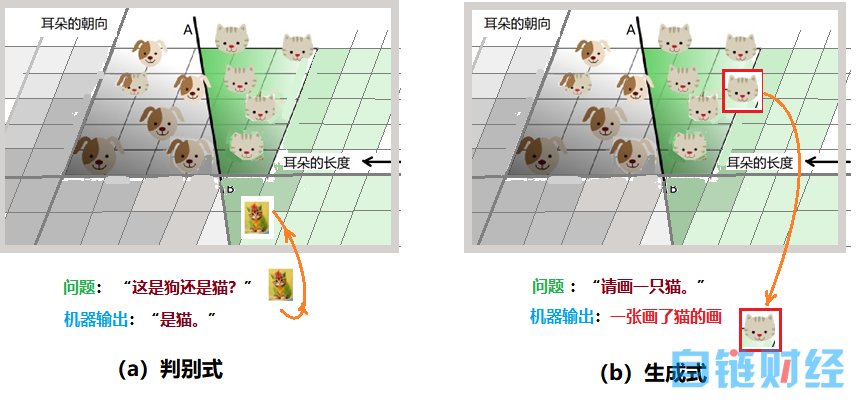
图 5:判别式和生成式的区别
还用识别“猫狗”的例子,用妈妈教孩子来打比。妈妈给孩子看了很多很多猫和狗样本之后,指着一只猫问孩子,这是啥?孩子回忆后作出判断“是猫”,这就是判别式。孩子答对了很高兴,自己拿起笔,在纸上画出一个脑海中猫的形象,这就是生成式了。机器的工作也类似,如图 5 所示,判别式中,机器寻找判别需要的分界线,以区分不同类型的数据实例;生成式模型则可以区分狗和猫,最后画出一只“新的”动物照片:狗或猫。
用概率的语言:设变量 Y 代表类别,X 代表可观察特征。判别模型是让机器学习条件概率分布 P (Y|X),即在给定的特征 X 下类别为 Y 的概率;生成模型中机器对每一个“类别”都建立联合概率 P (X,Y)的模型,因而可以生成看起来像某种类型的“新”样本。
例如,类别 Y 是“猫、狗”(0,1),特征 X 是耳朵的“上、下”(1,2),假设我们只有如图所示 4 张照片:(x,y)= {(1,1),(1,0),(2,0),(2,0)}
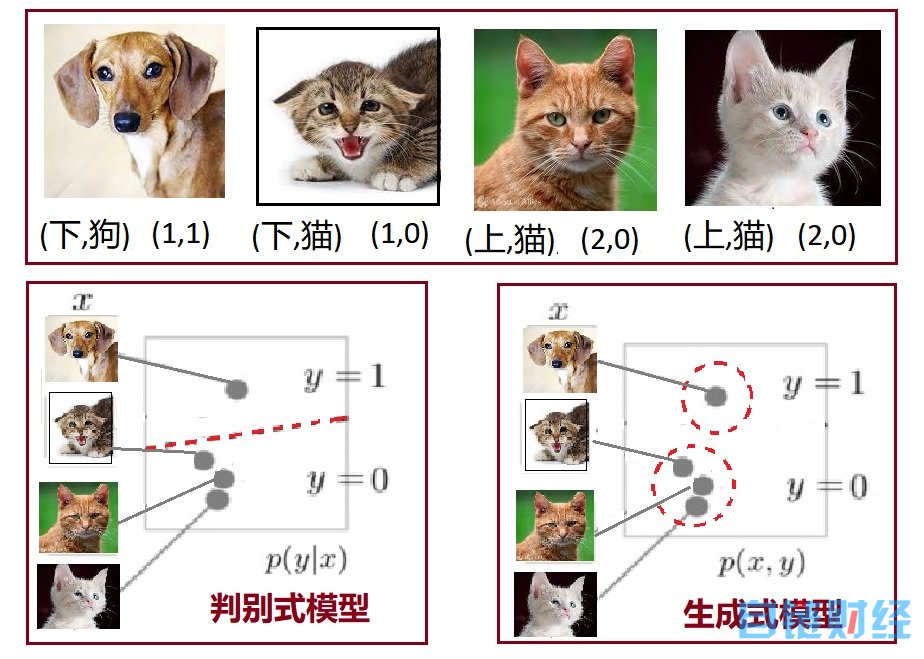
图 6:判别式和生成式建模的区别
判别式由条件概率 P (Y|X)建模,得到分界线(左下图中的红色虚线);生成式由联合概率 P (X,Y)为每种类别建模,没有分界线,但划分了每个类型在数据空间的位置区间(右下图中的红色圆圈)。两种方法根据不同的模型给出的概率来工作。判别式更简单,只在乎分界线;而生成式模型要对每个类别都进行建模,然后再通过贝叶斯公式计算样本属于各类别的后验概率。生成式信息丰富灵活性强,但学习和计算过程复杂,计算量大,如果只做分类,就浪费了计算量。
几年前,判别式模型更受人喜爱,因为它用更直接的方式去解决问题,早就得到了不少的应用,比如垃圾邮件和正常邮件的分类问题等。2016 年的 alphago 也是判别式应用作决策的典型例子。
ChatGPT 的特点
如果你跟 ChatGPT 聊过天,一定会惊奇于它的涉猎极广:创作诗歌、生成代码、绘画作图、撰写论文,似乎样样在行,无所不能。是什么赋予了它如此强大的功力呢?
从 ChatGPT 的名字,我们知道它是一个“生成型预训练变换模型”(GPT)。这里包括了三个意思:“生成型“、”预训练“、”变换模型”。第一个词,点明它用的正是上面所介绍的生成型建模方法。预训练,说的是它经过了多次训练。变换模型是从“transformer”的英文翻译过来的。变换器 transformer 于 2017 年由谷歌大脑的一个团队推出,可应用于翻译、文本摘要等任务,现被认为是处理自然语言等顺序输入数据问题 NLP 的首选模型。
如果你问 ChatGPT 自己,“它是什么?”之类的问题,一般来说,它都会告诉你,它是一个大型的 AI 语言模型,这模型指的就是 transformer。
这一类的语言模型,通俗的意思就是一个会“文字接龙”的机器:输入一段文字,变换器输出一个“词”,对输入文字进行一个“合理的延续”。(注:这儿我说输出是一个“词”,实际上是一个“token”,对不同的语言可能有不同的含义,中文可以是“字”,英文可能是“词根”。)
其实,语言本来就是“接龙”。我们不妨思考一下孩子学习语言和写作的过程。他们也是在听大人说了好多遍各种句子之后学会怎么说一句话的。学写作也类似,有人说:“熟读唐诗三百首,不会作诗也会吟”,学生看了大量别人的文章后,开始学写作时,总会有所模仿,实质上就是无意识地学会了“文字接龙”。
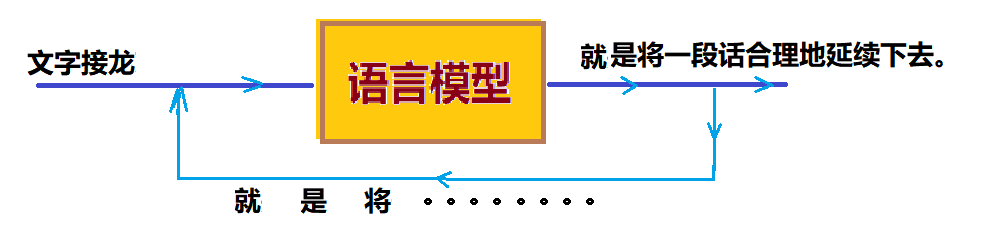
图 7:语言模型
所以实际上,语言模型所做的事情听起来似乎极为简单,基本上只是在反复地询问“输入文本的下一个词应该是什么?”,如图 7 所示,模型选择输出了一个词之后,把这个词加到原来的文本中,又作为输入进入语言模型,又问同样的问题“下一个词是什么?”。然后,再输出、加进文本、输入、选择……如此反复循环,直到生成一个“合理的”文本为止。
机器模型生成文本的“合理”或不合理,最重要的因素固然是所用“生成型模型”的优劣,再就是“预训练”的功夫。在语言模型内部,对应一个输入文本,它会产生一个可能出现在后面的词的排序列表,以及与每个词对应的概率。例如,输入是“春风”,下一个可能的“字”很多很多,暂且只列举 5 个吧,可以是“吹 0.11、暖 0.13、又 0.05、到 0.1、舞 0.08”等等,每个字后面的数字表示它出现的概率。换言之,模型给出了一个带有概率的(很长的)单词列表。那么,应该选择哪一个呢?
如果每次都选择概率最高的那一个,应该是不太“合理”的。再来想想学生学习写作的过程吧,虽然也是在“接龙”,但是不同的人、不同的时候,有不同的接法。这样才能写出各种不同风格、又有创意的文章来。所以,也应该给机器随机选择不同概率的机会,才能避免单调平淡,产生出多姿多彩趣味盎然的作品。尽管不建议每次选择概率最高的,但最好选择概率偏高的,做出一个“合理的模型”。
ChatGPT 是大型语言模型,这个“大”首先表现在模型神经网络权重参数的数量上。它的参数数目是决定其性能的关键因素。这些参数是在训练前需要预先设置的,它们可以控制生成语言的语法、语义和风格,以及语言理解的行为。它还可以控制训练过程的行为,以及生成语言的质量。
OpenAI 的 GPT-3 模型具有 1750 亿参数量,ChatGPT 算是 GPT-3.5,参数数量应该多于 1750 亿。这些参数指的是在训练模型前需要预先设置的参数。在实际应用中,通常还需要通过实验来确定适当的参数数量,以获得最优的性能。
这些参数在成千上万的训练过程中被修正,得出一个好的神经网络模型。据说 GPT-3 训练一次的费用是 460 万美元,总训练成本达 1200 万美元。
如上所述,ChatGPT 的专长是生成“与人类作品类似”的文本。但一个能够生成符合语法的语言的东西,未必能够进行数学计算、逻辑推理等等另一些类型的工作,因为这些领域的表达方式完全不同于自然语言文本,这也就是为什么它在数理方面的测试中屡屡失败的原因。
此外,人们也经常发现 ChatGPT“一本正经地胡说八道”的笑话。其原因不难理解,主要还是训练的偏向问题。某些它完全没有听过的东西,当然无法给出正确的回答。还有多义词带来的问题,也给机器模型困惑。例如,据说有人问 ChatGPT“勾三股四弦五是什么”的时候,它一本正经地回答说:“这是中国古代叫做‘琴’的一种乐器的调弦方法,然后还编造了一大堆话,令人捧腹不已。
总之,ChatGPT 一上场就基本取得成功,旗开得胜,这也是概率论的胜利,贝叶斯的胜利。
参考文献
1. 张天蓉。趣谈概率 – 从掷骰子到阿尔法狗 [M]. 北京:清华大学出版社,pp.71-75,2017 年
2.Sean R Eddy,“What is Bayesian statistics?”,[J], Nature Biotechnology 22, 1177 – 1178 (2004) .
3.Jake VanderPlas,“Frequentism and Bayesianism: A Python-driven Primer”,[L], arXiv:1411.5018 [astro-ph.IM],2014. https://arxiv.org/abs/1411.5018
4.Russell, Stuart; Norvig, Peter (2003) [1995]. Artificial Intelligence: A Modern Approach (2 nd ed.).[M], Prentice Hall. p.90