

策划、撰文 | Joel Li, Steven Shao
整编 | Sigrid Liu
据福布斯中国统计,今年以来,全球一共有至少280家人工智能相关的初创公司完成新一轮融资,占融资案例总数的5.9%,环比上个季度上升1.3%。在短短的90天内,大语言模型撬动的商业化机会似乎已经短暂地超过了VR、AR、机器人等硬件科技赛道,成为2023最值得关注的创业领域。
虽然如OpenAI这样的AGI(通用人工智能)头部公司已经产生,全球互联网巨头们的大语言模型项目接连上线也开始变得乏味,但这并不妨碍初创公司们前赴后继加入战场。过去3个月中,全球基于大模型新成立的AI公司数量达到28家。
– 美国(16家),代表项目:Fixie / NuMind / Tavus / Capsule Video / Seek AI / Poly,inc
– 中国(9家),代表项目:光年之外 / 百川智能 / Project AI 2.0等
– 欧洲(5家),代表项目:德国Kern AI / 西班牙Argilla / 法国SESAMm
新一轮AI技术马拉松已经跑完最精彩的头5分钟,我们见证了全球科技行业久违的沸腾。然而,仅比较各地创业公司关注方向,美国聚焦应用的初创人工智能公司数量正在迅速甩开中国和欧洲。而落后的全球另外两大风险投资阵地仍然毫不犹豫地将资金更集中地投入到有可能做出对标ChatGPT这一划时代产品的本土公司。
因为自OpenAI开放API短短几周内,多模态的大语言模型已经成功被当作下一代人工智能的基础设施。
Part.1 决战大模型
如果要让AI更快地走进市场,训练大模型是中国公司目前无法绕过的一座大山。但好消息是,过去3周内为我们反馈调研问卷的AI公司中,仅有30%的样本认为在该领域存在算法技术上的明显壁垒,远远低于:
73%的公司表达了对当前算力成本限制的担忧;
76%的公司承认了技术合规方向上全球目前还没有令人信服的实践框架(其中涉及伦理、知识产权以及数据安全等三个方面的主要问题);
43%的公司认为数据封闭会影响整体模型开发。
而以上这三点也是全球所有大语言模型公司迈向商业化需要直面的问题,同时也更为致命。
事实上,对于新一代AI技术公司,目前也仅仅只在算法上具有相对的确定性。因为人工智能技术路径的迭代持续了近50年,今天几乎所有的大模型算法研究在历史上都有迹可循。
如为ChatGPT奠基的神经网络Transformer一定程度上借鉴了Jürgen Schmidhuber团队1993年在慕尼黑工业大学发表的一种Transformer变体,这也是最早提出的一种通过快速权重编程器将存储和控制分离,实现端到端可微分,自适应的方式进行信息传递、处理的算法。
在4月初,福布斯中国与“LSTM之父”Jürgen Schmidhuber教授的采访中,谈及大模型当下的竞争格局以及美国、中国和欧洲的机会,他认为,“虽然深度学习的大部分基础算法是由欧洲人发明的,但美国的大公司在商业化这些算法方面做得更好。事实上中国的公司并不落后。这些基本方法已经是开源的。你们需要的是更快的计算机,大量的数据和工程人才。”
但初创公司与巨头的博弈还会存在很长一段时间。
以往,一次信息技术的革命往往会降低创业门槛,这被概括为信息技术普及的红利。而这一轮的技术变革虽然由OpenAI等创业公司挑起,但在高昂的算力成本以及数据使用难度等客观限制条件下,创新在很短时间内就演变成为大公司的角力场以及军备竞赛,也很快盖过本应属于创业公司的风头。
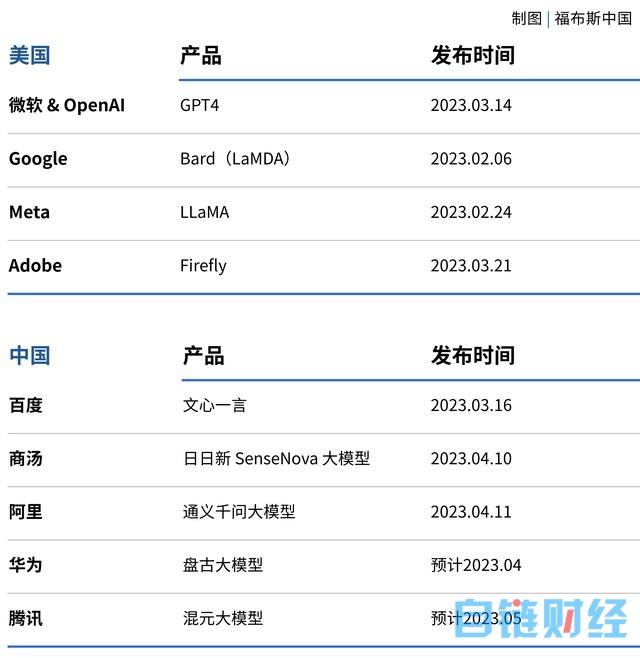
自2月以来,中国和美国一共有9个互联网大厂推出大模型驱动的AI产品或发布新的大语言模型。这些产品很大程度定义了当前的产业话语权。

但这并不意味着初创公司没有机会,Jürgen Schmidhuber教授对此保持相当的乐观。他认为现在很多人关注的地方在于摩尔定律中处理器的性能两年翻一倍这一事实,但是对于人工智能技术的普及则是要依靠一个更古老的规律。自1935年Konrad Zuse创建了世界上第一台工作的可编程通用计算机后每5年,计算机的成本就会便宜10倍。同样对于今天的人工智能,每5年,他们的价格也将便宜10倍。21世纪将出现具有比所有人类大脑的原始计算能力多一千倍的廉价计算机组合。
不可否认的是,今年也是中国风险投资历史上互联网创业门槛最高的一年;中国的明星创业者和知名投资人们正准备复刻OpenAI式的成功。
过去3个月中,一共有6家大语言模型公司浮出水面。这些项目在成立的几个月内平均估值就超过2亿美元,其中还有2家目前水下估值据传已经达到独角兽级别。虽然这些项目的融资水平还未能触及OpenAI成立时,阿尔特曼与埃隆·马斯克等人宣布为其注资的10亿美元,但考虑到目前的技术、确定性以及相较五年前算力成本下移等因素,在当下也不能算便宜。
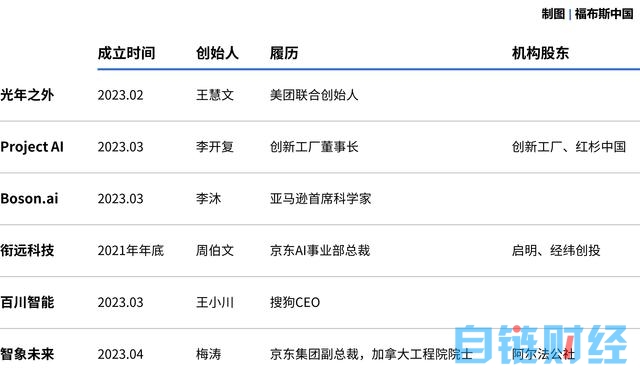
同时受到OpenaAI盈利分配的启发,中国AI创业项目的叙事逻辑也发生了改变。如王慧文所创立的光年之外承诺个人出资5,000万美元,估值2亿美元;个人劳动力不占股份,资金占股25%,75%的股份用于邀请顶级研发人才。
此外,王小川所创立的百川智能近期官宣的5,000万美元新一轮融资由自己与其业内好友的个人支持。此前王小川在微博中表示:“OpenAI的成功,首先是技术理想主义的胜利。中国需要自己的OpenAI,就需要技术理想主义。大厂受限于自己的业务牵引,追逐资本热点的创业公司动作更容易变形。不止如此,这种理想主义还需要有爱国之心、商业智慧和学术尊重去获得政府支持、推动企业联盟和学术界协同。我相信中国能诞生自己的OpenAI。”
至此,大模型赛道迎来了中国创业市场最不差钱的一群创始人。同时,这类群体极有可能会改变中国科技产业的文化,因为我们看到了一种对承担风险更加开放的态度。
但有关大模型赛点的真正到来或许还需要较长时间,这涉及到人工智能技术的成本。
Part.2 新的产品逻辑魅影
一场技术到应用的赛跑刚刚开始。如果说OpenAI被理解为如苹果一样的封闭系统,那么Google的LaMDA则再次被看作是安卓。虽然关于大模型这一底层基础设施不确定性的因素仍有很多,但确定的是,从以往的单模态到多模态AI大模型的过渡正在成为一种新的游戏规则。
我们收集到的样本案例同样证明了这一点:成立3年以上的AI公司中有至少一半向我们强调,多模态的应用对于场景探索有着革命性的帮助。
多模态:将多种感官进行融合,而多模态交互是指人通过声音、肢体语言、信息载体(文字、图片、音频、视频)、环境等多个通道与计算机进行交流,充分模拟人与人之间的交互方式。
除OpenAI外,从今年已经官宣的中美10个最大的AI融资案例看,至少有8家公司明确走向多模态应用方向;探索语言、文本、图像与人的互动关系,是构建下一代人工智能场景的究极密码。

中国的大模型AI公司有4家进入到融资金额排名前十位;而前OpenAI员工离职所创办的两家公司Adept AI与Anthropic则分别拿到最多的钱。
Adept AI创始人戴维·栾 (David Luan) 曾任OpenAI的工程副总裁。Adept团队希望出品一款基于自然语言处理和人工智能技术产品,实现通过语音或文字输入来完成各种操作和任务,取代传统的应用程序或界面。该产品具有极高的智能和自适应能力,可以根据用户输入的指令和需求自动寻找最优解决方案,并执行相应的操作。
另外一个由OpenAI分裂出的团队Anthropic则开始致力于解决长久以来神经网络的“黑盒子”问题,为研究者们开发能够解释AI真正工作原理的工具,同时为人工智能技术落地提供安全性保障。
此外,在2023年第一季度拿到第三大融资的是前谷歌员工创办的Character.ai。在今年拿到了由a16z领投的1.5亿美元后,公司估值达到独角兽级别,同时也意味着首个AI驱动的聊天软件平台出现了。
中国人工智能初创公司心识宇宙的CEO陶芳波认为AI将颠覆产品学,并成为所有软件的入口。这位曾供职于美国微软研究院、Facebook Research、NASA和阿里达摩院神经符号实验室的博士解释称:“过去所有的软件应用构建的基础在于将人与服务相互链接,产品经理们捕捉需求,用图形界面集成信息,最终引导用户下达指令、调用数据、完成交付。这虽然高效但是缺乏深度整合能力。下一代的互联网产品将更加AI原生 (AI Native Service) ,随着越来越强大的AI出现,图形界面的交互方式将会被弱化。更大的机会在于创造一种更加AI的交互方式。”
Part.3 AI与更接地气的应用
或许重塑人机互动逻辑这样宏大的愿景离商业成功还需要很长时间,相反新技术与旧功能之间搭配所产生的化学效应让人始料未及。
截至3月底,内置GPT4技术的微软Bing,日活用户数量已经超过1亿,单月访问量增长16%,下载量暴增8倍。而同期谷歌开始受到冲击,应用下载量降低1%。投资机构D.A. Davidson认为,“如果谷歌继续推迟将生成式AI技术集成到其产品中,那么Bing将在未来几个月内获得搜索市场更多的份额。”
这意味着,新的人工智能技术已经有机会撼动上一代互联网基石级别的产品——搜索。Google近期的弱势表现,也让互联网最大的蛋糕“广告投放”变得充满变数,以万亿美元经济价值计算的互联网广告相关公司不得不迎接变化。
此外,由大语言模型推动的软件生产力工具“革命”同样无法忽视。如上个月,微软发布了基于GPT4技术的Copilot,它将适用于Word、PowerPoint、Excel、Outlook、Teams等微软商业软件。几乎前后脚,Adobe也同时发布了生成式AI制图工具Firefly,未来将全面扩展到旗下的Photoshop、Illustrator以及Premiere等产品中。
如果说Bing在过去一个月的成功是通过GPT4的技术缩短用户从问题到答案的距离,进而创造一种比Goggle更好的搜索体验,那么进一步看,AI已经有能力改变一部分用户的搜索习惯。
为互联网这个无比巨大的图书馆创造一个足够智慧的图书管理员会发生什么?用户在进入图书馆后一定会先询问这个图书管理员。这也意味着搜索产品的性质迎来颠覆式的变化。
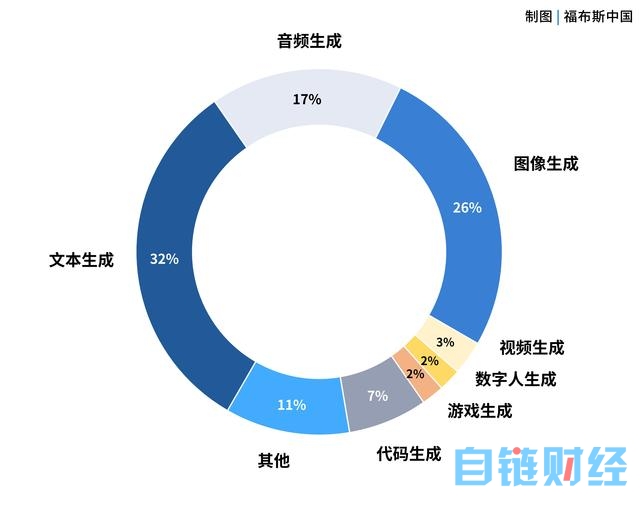
以上猜想已经部分得到验证。我们在过去的3周向数百家中国人工智能公司投送了调研问卷。从采集的反馈看,工具类型的产品毫无疑问占据了主流。目前来看,文本生成、图像生成等仍然是中国本轮应用创新的主阵地,其次则是数字人以及游戏生成等。
而对于软件、企业服务领域而言,AI功能的植入已经成为不可逆的趋势,但它们目前还很难成为多项应用的入口。
Part.4 我们最应该关注谁?
我们筛选了20位今年以来在中国人工智能领域日渐活跃的KOL,期待他们讲出中国AI新故事。以下排序不分先后。
周伯文
衔远科技创始人
周伯文博士目前是清华大学惠妍讲席教授、电子工程系长聘教授,2022年5月亦创建并领导清华大学电子系协同交互智能研究中心,拥有二十多年自然语言生成、对话与交互式人工智能的研究经验,他2016年提出的自注意力融合多头机制的自然语言表征机理是Transformer架构的核心思想之一,被Transformer、GAT等论文引用超过2,000次;在AIGC领域,他提出的自然语言生成算法被引用3,000余次。
周伯文博士创业前为原京东集团高级副总裁、集团技术委员会主席、云与AI总裁,京东人工智能研究院院长。此前,他在美国学习与研究人工智能近20年,为原IBM Research美国总部人工智能基础研究院院长、IBM Watson集团首席科学家、IBM杰出工程师。2021年年底,他创立衔远科技,以前沿的人工智能技术帮助企业数实融合,实现从需求洞察到产品创新全过程数智化,颠覆式地完成以消费者为中心的产品创新。
杨植麟
循环智能联合创始人
杨植麟博士是循环智能(Recurrent AI)联合创始人,智源青年科学家。由杨植麟博士带领研发的产品及解决方案已成功应用于银行、保险、房地产和汽车等行业,日均处理对话超一亿次、覆盖数百万终端用户。其研究成果累计Google Scholar引用超过16,000次(2023年2月统计);作为第一作者发表Transformer-XL和XLNet,对NLP领域产生重大影响,分别是ACL 2019和NeurIPS 2019最高引论文之一;主导开发的盘古NLP大模型获2021年世界人工智能大会”卓越人工智能引领者之星奖”;曾入选2020年“2020福布斯中国30岁以下精英榜”;曾效力于Google Brain和Facebook AI,博士毕业于美国卡内基梅隆大学,本科毕业于清华大学。
蓝振忠
西湖心辰创始人
蓝振忠,卡耐基梅隆大学 (CMU) 人工智能博士,曾任谷歌人工智能研究院科学家,NLP自然语言处理领域训练语言模型“ALBERT”第一作者,2021年被麻省理工大学评选为亚太地区“35岁以下科技创新35人”之一。蓝振忠十几年致力于研究自然语言处理,计算机视觉,及深度学习的结合应用。2021年,他创立西湖心辰,专注于大模型的研究和应用。带领团队研发出国内行业领先的Al绘画“造梦日记”、AI写作“Friday” 、A心理咨询“聊会小天” 等平台级人工智能应用。
唐杰
清华大学教授
唐杰(ACM/AAAI/IEEE Fellow),清华大学计算机系教授,获国家杰青。研究人工智能、知识图谱、数据挖掘、社交网络和机器学习。发表论文300余篇,获ACM SIGKDD Test-of-Time Award(十年最佳论文)。谷歌引用超过2.8万。
2019年,唐杰博士参与创立智谱AI。2020年智谱AI研发 GLM 预训练架构并开始训练百亿参数模型,2022年进一步推出高精度开源千亿模型 GLM-130B,斯坦福报告显示 GLM-130B 是性能上可与 GPT-3 基座对标的双语开源模型,已有55个国家和地区989家机构申请使用。2023年2月,智谱AI联合清华大学研发了ChatGLM,该模型基于GLM-130B 持续进行文本和代码预训练并通过有监督微调等技术实现人类意图对齐;支持英伟达和华为昇腾、海光及申威等国产芯片进行训练和推理,开源的 ChatGLM-6B 模型全球下载超过70万,持续两周位列 Huggingface 全球模型趋势榜榜首。
沈向洋
香港科技大学校董会主席、IDEA研究院理事长
沈向洋博士是IDEA研究院创院理事长、美国国家工程院外籍院士、英国皇家工程院外籍院士,是计算机科学领域的专家和科技产业领袖,在学术界、企业界、投资界拥有重要影响力。他曾任微软公司执行副总裁,负责推动中长期总体技术战略及前瞻性研究与开发工作;参与创建了微软亚洲研究院,并担任院长兼首席科学家,培养了众多一流的计算机科学家、技术专家和企业家。
黄民烈
聆心智能创始人
黄民烈,清华大学计算机系长聘副教授、情感对话系统开创者、聆心智能公司创始人。著有国内第一本关于自然语言生成的著作《现代自然语言生成》。其引领的团队是国内最早从事大模型研发的团队之一,自研全球 TOP1的中文对话大模型OPD,并率先推出了国内首个大模型安全评估框架。以自研超拟人大模型为底座,打造了机器属性与人格属性统一的对话智能体,推出产品AI乌托邦。
周明
澜舟科技创始人兼CEO
周明是澜舟科技创始人兼CEO,现任中国计算机学会副理事长、创新工场首席科学家、中国人工智能学会会士和五所大学的博士生导师,世界NLP领域的领军人物,世界上发表ACL论文最多的学者之一。曾任国际计算语言学学会主席、微软亚洲研究院副院长,长期领导微软亚洲研究院的NLP研究,在计算机创作、机器翻译、搜索、推荐、预训练模型等领域获得世界领先的研究成果并广泛应用于微软的各类产品中。2021年创立认知智能公司澜舟科技,该公司致力于开发最先进的下一代认知智能技术,包括自然语言和多模态信息的理解和生成、机器翻译、知识图谱、问答和推理、行业搜索、知识服务等技术。
何晓冬
京东副总裁
何晓冬博士二十多年来从事自然语言处理和语言与视觉多模态智能等人工智能领域的研究,是本领域世界级科学家。加入京东之前,何晓冬博士就职于美国微软雷德蒙研究院,担任首席研究员及深度学习技术中心负责人。他发表了200多篇论文,引用4万余次。他多次获得ACL杰出论文奖、IEEE SPS最佳论文奖等奖项,他领导团队聚焦智能技术的前沿突破及智能服务与产品打造,大规模赋能政务、医疗、零售、金融等产业,并获得 2022年获得京东集团优秀管理者奖。他拥有清华大学学士学位及密苏里大学博士学位,同时在华盛顿大学(西雅图)等院校兼任教授。
田奇
华为云人工智能领域首席科学家
田奇教授,现任华为云人工智能领域首席科学家,IEEE Fellow。田奇曾任美国德克萨斯大学圣安东尼奥分校计算机系正教授,华为诺亚方舟计算视觉首席科学家;长期从事于计算机视觉多领域研究工作,现为清华大学神经与认知计算中心、中科院计算所、中科大、浙江大学、上海交通大学、西安交通大学、西安电子科技大学等讲席教授或者客座教授,兼职东南大学博导。
王海峰
百度首席技术官
王海峰博士先后创建和发展了自然语言处理、知识图谱、语音、图像、机器学习和深度学习等百度人工智能技术方向,先后负责百度搜索、百度地图、百度翻译、百度智能云等业务。
王海峰是自然语言处理领域世界上最具影响力的国际学术组织ACL (Association for Computational Linguistics) 历史上首位华人主席 (President) 、ACL亚太分会创始主席、ACL Fellow,还是IEEE Fellow、CAAI Fellow及国际欧亚科学院院士等。王海峰任深度学习技术及应用国家工程研究中心主任,兼任中国电子学会、中国中文信息学会、中国工程师联合体副理事长等。
周靖人
阿里云智能集团首席技术官
周靖人,哥伦比亚大学计算机博士,IEEE Fellow,拥有几十篇顶级会议和期刊论文,并持有多项专利发明。研究领域包括基于大规模分布式系统的数据计算处理方法和机器学习算法平台。曾任微软研究院研究员、微软研发合伙人。
杨红霞
前阿里巴巴达摩院人工智能科学家
杨红霞,美国杜克大学统计学博士毕业,前阿里巴巴达摩院人工智能科学家,带领团队探索认知智能技术在阿里的发展与落地;发表人工智能领域国际会议、期刊文章80余篇,取得美国和中国专利近20项。她曾带领团队获2019年世界人工智能大会SAIL奖、2020年国家科学技术进步奖二等奖(第三完成人)、2021年中国电子学会科学技术进步奖一等奖(第二完成人)等荣誉。杨红霞曾任IBM全球研发中心Watson研究员和Yahoo!计算广告首席数据科学家;2022年6月,入选2022福布斯中国科技女性50;2022年10月从阿里达摩院离职。
王慧文
光年之外创始人
王慧文,互联网连续创业者,曾参与创立校内网(现人人网)、来电网、淘房网。2010年,他加入美团,任联合创始人。2020年,王慧文宣布从美团退休。今年2月,他宣布成立光年之外,个人出资5千万美元,估值2亿美元,自有资金占股25%。
王小川
百川智能创始人
王小川是搜狗公司创始人,主导开发了搜狗搜索、搜狗输入法、搜狗浏览器等产品。他先后推动阿里巴巴和腾讯战略入股搜狗。2017年,他带领搜狗在美国纽交所上市。4月10日,王小川宣布,入局大模型赛道,公司名为“百川智能”,定位为一家研发并提供通用人工智能服务的中国公司。
李笛
小冰公司首席执行官
李笛,曾任微软(亚洲)互联网工程院常务副院长、微软小冰全球总经理及微软Bing搜索引擎亚洲区总经理。他于2013年加入微软,同年创立微软人工智能情感计算框架,并于2014年推出微软小冰。为加快小冰产品线的本土创新步伐,促进小冰商业生态环境的完善,2020年7月13日,微软宣布将小冰分拆为独立公司运营,并委任李笛为小冰公司首席执行官。
刘群
华为诺亚方舟实验室语音语义首席科学家
刘群,华为诺亚方舟实验室语音语义首席科学家,负责语音和自然语言处理研究,研究方向主要是自然语言理解、语言模型、机器翻译、问答、对话等。他的研究成果包括汉语词语切分和词性标注系统、基于句法的统计机器翻译方法、篇章机器翻译、机器翻译评价方法等。他曾任爱尔兰都柏林城市大学教授、爱尔兰ADAPT中心自然语言处理主题负责人、中国科学院计算技术研究所研究员、自然语言处理研究组负责人。2022年1月6日,刘群入选ACL Fellow。
黄铁军
北京智源人工智能研究院院长、北京大学教授
黄铁军,北京大学计算机学院教授,北京智源人工智能研究院院长,北京大学人工智能研究院副院长。黄铁军一直在积极推动构建类脑人工智能的技术路线:结构层次模仿脑,器件层次逼近脑,智能层次超越脑。黄铁军教授也是在中国人工智能领域重要的思想者,他此前提出,要先放下“理解智能”的迷思,以神经科学为基础,构建神经形态计算系统,再通过训练实现强人工智能。
郭传雄
字节跳动AI Lab团队总监
郭传雄,就职于字节跳动公司,从事机器学习系统、数据中心网络、硬件研发方面的工作。在加入字节跳动之前,他是微软研究院的研究员。他也曾在微软云计算部门Azure Networking从事研发工作。他的研究兴趣是理解、设计、并运营大规模高可用计算机系统。此前,他因对数据中心网络设计的贡献而入选IEEE Fellow。
杨斌
MiniMax联合创始人、技术合伙人
多伦多大学博士,师从人工智能国际顶尖学者Raquel Urtasun。发表高水平论文30余篇,谷歌学术引用7,000+,是英伟达2018年先锋研究奖及微软2021全球博士奖学金获得者。在2017年作为核心创始成员共同组建了全球第一个自动驾驶 AI 研发中心(Uber ATG R&D)。在2021年作为核心创始成员加入了无人驾驶初创公司 Waabi,发布了业界第一个全球领先的数据驱动神经渲染自动驾驶仿真环境。于2022年回国加入MiniMax。MiniMax是目前国内同时拥有文本、语音、视觉三个通用大模型引擎能力的创业公司。
张宏江
北京智源人工智能研究院理事长
张宏江博士是源码资本投资合伙人,目前也是智源研究院理事长。他是国际著名的多媒体领域的开拓者和意见领袖,是美国工程院外籍院士,国际计算机协会 (ACM) 院士和电气电子工程协会 (IEEE) 院士;曾担任微软亚太研发集团首席技术官及微软亚洲工程院院长,是微软亚洲研究院创始人之一并任副院长;曾在金山集团、猎豹移动、迅雷及世纪互联担任要职。
