


 来源:《科创板日报》
来源:《科创板日报》
编辑 邱思雨
近日,英伟达与慕尼黑大学等院校的研究人员联合发布了一篇有关视频潜在扩散模型(VideoLDM,Latent Diffusion Model)的论文,该模型能够将文本转换成视频,实现高分辨率的长视频合成。相关论文已经发表在预印本网站arXiv上。
研究人员给出“一个泰迪熊正在弹电吉他、高清、4K”等文本提示词后,运用VideoLDM,成功生成了相关视频(已转为GIF格式):

目前,VideoLDM生成视频的最高分辨率可达2048×1280、24帧。研究团队仅公布了论文和一些成品视频案例,暂未开放试用。
据介绍,相对来说,该模型对于训练和计算的要求较低。在文字大模型、文生图大模型发展迅速的当下,受限于视频训练数据的计算成本高昂以及缺乏大规模公开可用的数据集等原因,视频大模型的发展相对较慢。VideoLDM则成功解决了这个关键问题。
从原理上来分析,VideoLDM基于图像数据集预训练,并在此基础上加入时间维度以形成视频框架,最后在编码的视频序列上进行微调,得到视频生成器。
为进一步提高分辨率,研究人员从时间维度将其与扩散模型upsamplers对齐,并与真实视频对比验证,从而将其转换为时间一致的视频超分辨率模型。
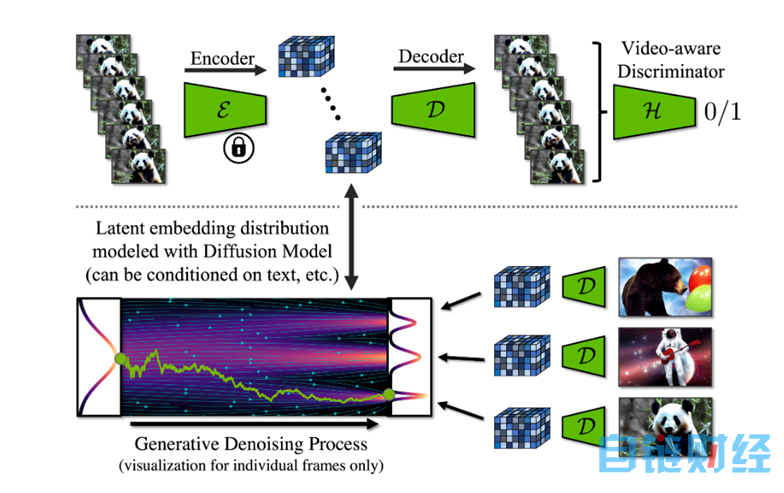
此外,研究人员还微调了Stable Diffusion,将其转换为视频生成器。他们通过对Stable Diffusion的空间层进行简单微调,然后插入时间对齐层,从而实现了视频的生成。
落实到应用层面,研究人员给出了两大具有潜力的应用领域:一是驾驶数据的高分辨率视频合成,能够模拟特定驾驶场景,在自动驾驶领域中具有巨大的应用潜力;二是创意内容的生成。
在论文中,团队给出了几个驾驶场景视频的生成案例:

目前,在自动驾驶领域,AI大模型被认为能够赋能感知标注、决策推理等环节。
华泰证券分析师黄乐平、陈旭东等于4月13日发布研报指出,AI大模型有望解决行业数据标注准确率及成本困境。该机构以DriveGPT为例进行分析,大模型能够将交通场景图像的标注费用从行业平均约5元/张降至约0.5元/张。
与此同时,机构还认为大模型将赋能场景生成、轨迹预测、推理决策等环节,能够根据驾驶场景序列数据,生成未来可能发生的多种驾驶环境并预测每种情况下车辆行驶轨迹。国泰君安亦指出AIGC将有助于自动驾驶的推进落地。