

现如今,人工智能发展迅速且日益受到重视,机器学习已经成为AI的核心技术。随着人工智能发展走向纵深,在AI三要素(数据、算力、算法)中,数据已成为其中的核心部分,并向着高质量化、高专业化的方向蓬勃发展,“数据为王”的时代已然来临。

人工智能在大数据、大模型的深度学习基础上,已经形成用大数据代替经验、用算法挖掘知识、用并行计算确保模型训练的可行性的基本范式。
UBS Global 研究报告发现:现如今AI工程师70%-90%的时间都花费在训练数据上。伴随着建模门槛的降低,数据的门槛却越来越高,使得训练数据变成了机器学习的瓶颈。
现阶段,工程师在标注方案以及对应的建模调试方面,在样本数据的均衡性、可视化、一致性以及准确性等数据治理方面都投入了大量的时间和精力,这也是训练数据过程中普遍存在的痛点。
日前,倍赛科技CTO刘世林博士应邀在第四届智能制造创新高峰论坛活动中,进行了以“打造Data-Centric MLOps基础设施,助力AI提效”为主题的演讲分享,总结了企业在人工智能工程应用方面的两大实践方向。

一个是基于中小型的模型,配合较多的“好数据”和较低的计算资源;
另一个方向则是使用大模型,用较少的“好数据”和较多的计算资源。
可以看出,两个方向都离不开“好数据”,所以,刘博士推荐企业AI的工程实践围绕Data-Centric MLOps的应用策略展开,更加便捷、高效地实现人工智能落地应用和产品交付。
作为打造Data-centric MLOps战略的第一步,倍赛科技研发了新一代支持多模态数据的AI训练数据平台X1,全新的X1从功能层面由四大板块构成,Ontology Center,Annotation Suite,Dataset Curation,SOTA Models。
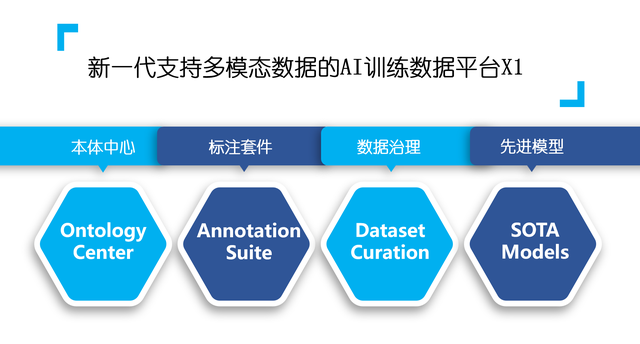
Ontology Center(本体中心)
本体中心是倍赛科技过去在执行了数万标注项目后重点打造的产品功能,将人工智能训练数据与模型之关系在各行各业应用发展积累下来的Know-How进行了抽象化的总结,目前已积累了数千个本体,覆盖了自动驾驶、医疗、零售、工业、安防、金融等多个行业。
X1可以自动分析用户训练数据的特征并给出最佳的本体推荐,从而帮助企业快速定义AI的问题和数据到模型的需求规范,让企业把更多的精力聚焦在解决问题而不是定义问题。
Annotation Suite(标注套件)
倍赛的标注工具套件经历了6年的打磨,已完成了两大的技术升级和改造。首先是从支持传统的单一数据类型,如文本、图像、视频、语音、点云等,升级至支持新的多模态数据类型,比如文本+图像,图像+点云,视频+语音等等,可以支持更丰富的建模需求和场景。
其次是半自动的智能标注,倍赛目前已经支持了从语音、文本、图像、视频、点云等全类型的预识别模型的功能,平均达到30%以上效率提升。
Dataset Curation(数据治理)
X1的数据治理模块主要解决企业数据多、数据乱、质量不一等问题,新的平台除了设计了全新的交互界面和统计面板以提升QC和数据管理的效率,还大量引入了AI能力的加持,比如标签的自动生成、数据的智能排序、搜索、批量修改等实用功能。
同时为了降低客户在数据投入上的成本,X1实现了Active Learning的技术帮助客户寻找最有价值的数据,也集成了很多数据增强的技术来解决客户数据的长尾问题。最后,数据治理模块也开放了SDK和API方便用户对接离线数据或实时数据,实现了人工智能应用闭环。
SOTA Models (先进模型)
X1不光光是解决了建模过程的数据软件问题,而且配备了最新的先进算法、预训练模型、开放接口的对接客户模型,从而解决很多客户建模工具碎片化的问题。对于没有AI背景或高级算法工程师的企业或个体来讲,可以只需要往平台输入数据和简单标注,无代码或低代码即可完成后续的模型训练和部署。同时,倍赛在各行各业经验积累也形成了倍赛独特的预训练模型的优势,帮助特定行业实现更低成本更好效果的AI落地。
据Gartner预测:到2025年,人工智能和数据科学平台市场将以21.6%的复合年增长率增长到超过100亿美元。正是因其巨大的市场需求,倍赛科技将6年多的AI实践经验,凝聚成了全新的Data-centric MLOps X1,首次向全球面世。X1不光光提供SaaS版的公有云软件,也提供便捷的“一键式私有化部署”,解决有数据隐私和数据安全需求的客户。完成了从“标注平台”到“一体化AI基础设施方向”的晋阶,构建最易于访问的Data-Centric MLOps,用于连接人、模型和数据。
